3d Reconstruction for Embodied Grasp Task
借助3d视觉重建构建泛化能力更强的具身智能Agent
Words
- manifest 表明,货单 The experiment results manifest
- designate 指派,指定
- undertake 承担
- underscore 强调
- jumbled 混乱的
- harness 控制,利用 attempts to harness the sun light
- canonical 典型的
- accommodate 适应,顺应
Distilled Feature Fields Enable Few-Shot Language-Guided Manipulation
TL;DR
借助蒸馏特正常去集合精确的3D信息和2D生成模型的几何信息,实现了开放世界物体的6自由度自动抓取和放置任务。作者认为在一个开放世界物体抓取任务中需要关注两类信息
- 几何信息,用于控制抓取的具体位置和姿态
- 语义信息,用于物体识别
任务
给定一些demonstration和文本描述,抓取novel object(基于预训练图像模型和大规模互联网数据实现泛化)
Method
采用类似的方法,渲染Distilled Feature Field,借助DFF实现开放场景下物体操作任务的泛化
建议读读Feature Field Distillation,提供了一种可编辑的Nerf范式
Overview
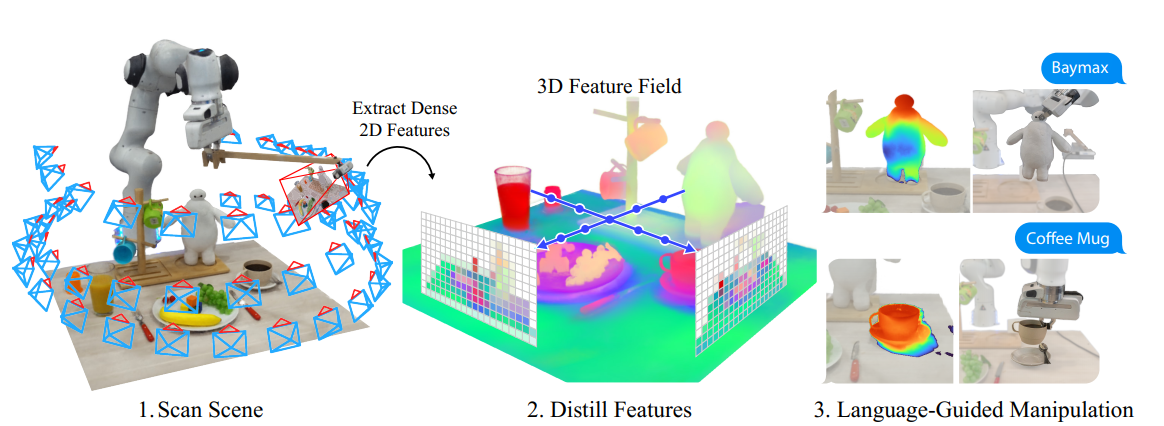
- 机器人借助自拍杆获得环境场景的RGB图像(场景扫描)
- 对patch层次的图片基于预训练模型获取2D representation,将其用于训练Feature Fied
- 基于新的视角获取feature map,基于CLIP计算哪些patch和我们关心的novel object相关(query with text embedding)
FFD
Nerf的渲染实际上在求解积分
其中$T(t)$是$[t_n,t]$区间的累计不透明度,这里我们的目标是渲染颜色,FFD相比Nerf的区别是希望构建线性模型从$(x,d)$预测$(c,\sigma)$修改为预测视觉feature vector $f(x)$,这里feature vector是视角无关的,这种情况下积分写成
$r_t$代表光线
训练:特征蒸馏
给定N张多角度RGB图片的Feature Map $I_i^f = f_{vis}(I_i)$,希望优化$F_r$到$I_i^f$之间的距离
Extracting Dense Visual Features from CLIP
希望做一个Language-guide的Agent,因此选择CLIP视觉分支输出的Embedding避免在后续过程中需要显示和Text对齐带来的视觉开销,作者做了两点改动以适应我们的任务
- Mask CLIP一张图获取多个Representation(CLIP直接对整张图做表征)
- Interpolate position encoding适应更大的图(CLIP训练将图片划分为的patch数量过少)
Representing 6-DOF Poses with Feature Fields
基于若干Demonstration,获取对应任务的task embedding,并根据其对6-DOF进行优化
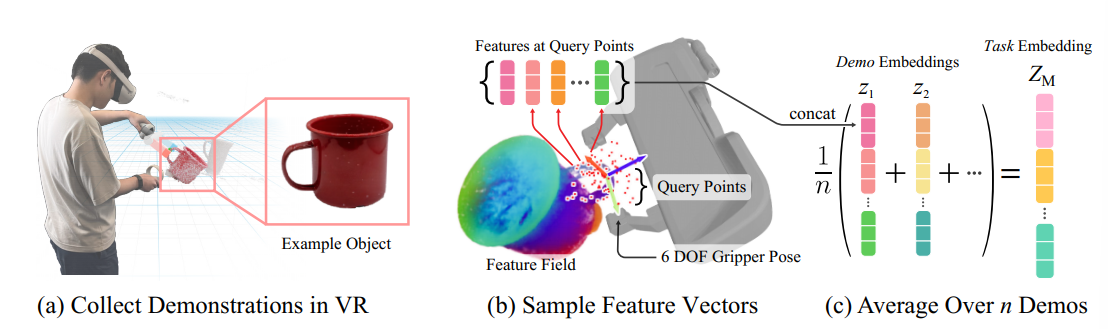
随机在空间中采样$N_q$个离散点作为query $\mathcal X = \{x\in R^3\},|\mathcal X| = N_q$,根据特征蒸馏场获取其特征
- 获取几何特征:作者任务Nerf渲染出的$\sigma$代表空间是否存在物体,将其和feature相乘得到$\alpha-$feature
基于这些feature获取task embedding $Z_M \in \R^{N_q\times |f|}$,对于每个task我们获取一系列demonstration,记作
- 基于task embedding的优化,对于当前的pose T,我们获取上述的task embedding $z_T$,优化目标是
Open-Text Language-Guided Manipulation
引入文本做open-world控制任务,引入自然语言表明需要操作的物体,这一步需要从已有的demonstration中选择和我们任务相似的demonstration,具体而言是通过计算demonstration的 average feature $F_d$,希望其和text embedding尽量相似
- 初始化姿态:基于text对feature field做query,过滤掉一些和操作物体无关的区域,给定若干negative queries $L_i^-,i=1,2,\cdots,n$和一个positive query $L^+$,计算采样的voxel feature和negative/positive query之间的相似度,拒绝和negative query相关度大于50%的voxel
- 基于文本优化Grasp Pose:基于retrieve的两个demonstration计算task embedding和pose embedding之间的相似度,得到$\mathcal L_{pose}(T) = -\cos(z_T,Z_M)$
- 同时希望我们在空间中得到的采样点集合$\mathcal X$尽可能和language query q相似,计算$q\odot f_\alpha(x)$并在空间所有离散点上做average $C_q = mean_{x\in T\mathcal X}[\cos{(q,f_\alpha(x))}]$
- 损失函数是Weight和Pose Loss乘积
Gaussian Grasper: 3D language Gaussian Splatting for Open-vocabulary Robotic Grasping
Words
- accommodate 适应,顺应
- pivotal 核心的
- pursuit 追求
- superfluous 多余的
- impose 强加于 Impose unpaid leave on staff
- feasible 可行的 (unfeasible 不可行的)
- canonical 典型的
- exhibit 展示 prohibit 禁止
Motivation
- 3d Q-A任务(给定文本基于3D模型找到对应物体)有助于帮助Agent完成基于语言的物体操作任务
- 采用空间的隐式表征(Nerf)需要多角度推理图片,推理过程需要多次采样因此效率低
- 本文借助3D Gaussian获得空间的显式表征,构建空间的feature field(Feature Distillation),对生成模型对语言的编码做蒸馏
Review of Previous Work
- 获取机器人操作任务中准确的3D位置
- 直接融合2D语义到3D点云或体素(多角度图像语义不一致)
- 借助3D模型和有监督范式学习
- 借助Distilled Feature Fields
- 只能获取patch-level的语义信息,导致不能准确定位
- 需要大量多角度图像用于训练
- 推理速度慢
- 无法处理场景变换
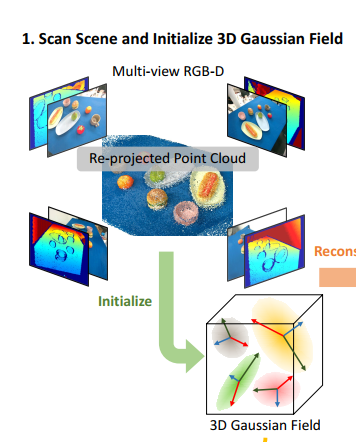
Overview of the Framework
利用多角度RGBD图像初始化3D Gaussian
学习Gaussian Field(Feature/Depth/Normal Field)
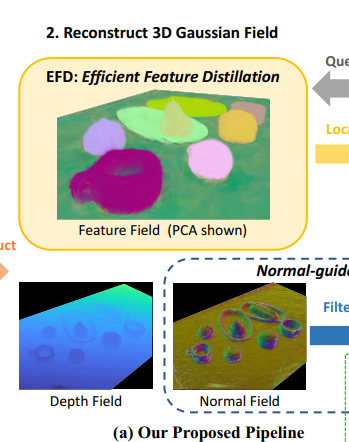
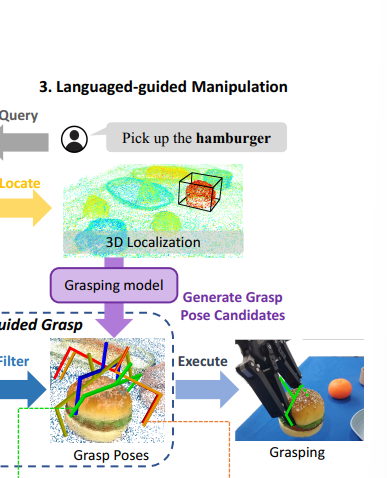
基于自然语言完成定位+抓取操作(Grasping Model)需要和重建的Gaussian Model进行交互
Feature Distillation
SAM+CLIP获取open vocabulary的物体描述
直接让3D Gaussian预测CLIP Embedding维度太大了不容易,希望模型预测Low-dimension latent space feature,渲染feature采用3D Gaussian类似的方法
其中$l_i$是一个低维的open-vocabulary feature embedding,作为Gaussian预测的一部分,需要将其恢复到原始Feature的dimension,这样会带来很大的计算和显存开销,本文基于对比学习做蒸馏,基本思想是一个SAM mask下的所有pixel对应的feature应该是一致的,因此计算的loss也是一致的,这种情况下将属于一个mask的两个pixel视为正样本
Language-guided Robotic Manipulation
基于language对3D表征做Query,定位目标物体
参考LERF,生成一个heatmap,对应每个像素和文本描述的相关程度,借助预先选择threshold进行filter
渲染深度和法线图,获取物体几何信息描述,法线图用于排除不可行的操作
- 渲染深度图:采用类似于3dgs的方法,采用一条射线和多个3Dgs相交,判断光线路径上相交多个Gaussian的距离并进行$\alpha-$blending,和Ground Truth比较
- 渲染法线图:选择3D Gaussian最短的轴方向作为物体表面发现方向,同理采取$\alpha-$blending进行渲染,渲染出pixel space上每个点在robot base空间上的法线方向,借助深度图生成的法线方向做监督
生成feasible grasp pose
Reference
- Lerf : Language embedded radiance felds
- Decomposing NeRF for Editing via Feature Field Distillation
- Anygrasp: Robust and effcient grasp perception in spatial and temporal domains