MAE
Masked AutoEncoder(CV中的Bert)
Motivation
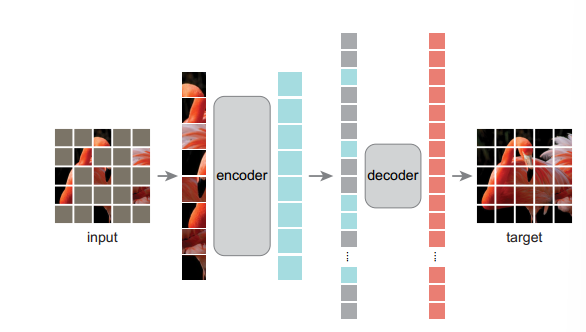
能否将NLP中用于半监督学习的方法(随机Mask掉一些Token)用于CV?本文随机Mask掉一些图片中的patch,希望通过一个Encoder-Decoder架构的Transformer将其复原。本文的另一大贡献在于提出了一个特殊的半监督学习任务:即Mask掉一张图片的大部分patches,输入包含未被mask掉的patches组成的序列,编码器输出的序列和masked token结合送给decoder,用于预测mask掉的patches是什么
本文归纳了NLP和CV任务的区别
- 解决CV的网络结构从卷积网络变为Vision Transformer
- 语言和图像的信息密度差别很大,语言中每个token包含人类生成的,充斥着语义信息。图片在空间上的信息非常荣誉
对于重建任务,NLP和CV任务的区别在于
NLP重建每个token,代表高维语义信息,而MAE中的Decoder输出像素级信息,代表图片的低维语义,因此Decoder的设计对于视觉重建任务而言极为重要
本文设计了一种非对称式的Encoder-Decoder架构,具体而言Encoder的输入包含所有未被Mask的Patch,这些patch经过Encoder编码得到的。对于Decoder而言,输入包含被mask掉的patch的representation和encoder输出patch的representation,通过一个轻量级网络重建整张图片。这样做保证了算法的效率以及使得Encoder输入端mask掉大部分patch变为可能。
MAE展示出了很高的泛化性
Method
Mask
作者认为输入端mask掉大部分patch的意义在于减少了图片数据中的信息冗余。本文尝试了多种mask的方式并最终选择了random mask,这种方式保证在图片不同部位均匀mask掉等量信息。
MAE Encoder
ViT
MAE Decoder
用一系列可学习的token填充mask patch在输出中的位置,并为所有patch representation添加positional embedding。Decoder仅仅为了预训练而设计,因此可以采取和Encoder完全不同的结构以减少计算开销
Loss Function
仅仅在masked patch上计算MSE Loss
Experiment
基于MAE学到的表征测试泛化性,具体实现有
- 端到端fine-tune整个模型
- 在表征后接上一个先行蹭
任务是图片分类,首先讨论了预训练时masked ratio对分类准确度的影响
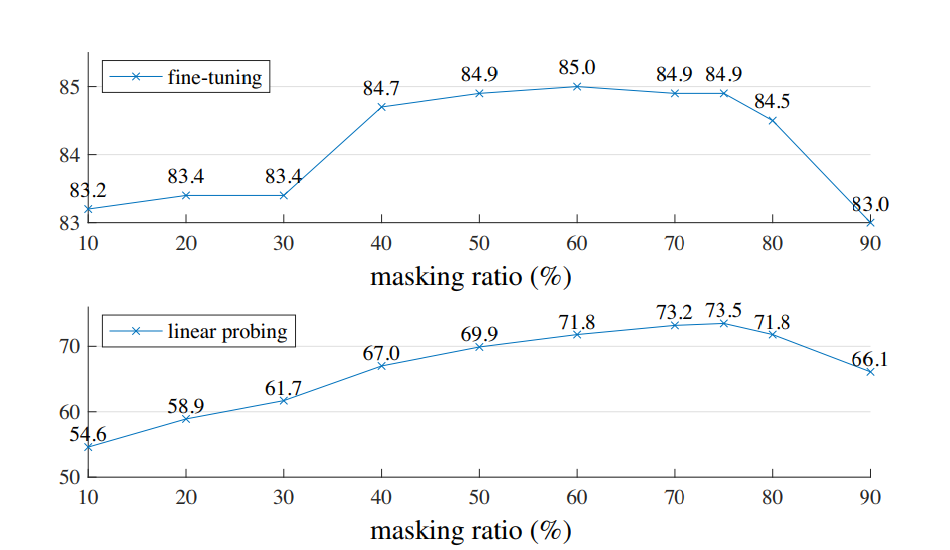
两种协议下,最佳的分类准确度对应的masked ratio大约为75%