ALBEF and BLIP
ALBEF and BLIP
BLIP(自举式生成图像-文本对数据以预训练更好的视觉语言模型)
现有视觉-语言预训练任务的局限性
- 无法统一图像理解和图像生成
- 基于包含大量噪音的数据集训练
本文提出caption generator解决问题2,利用filter过滤掉噪音文本,利用这种方式生成的文本相当于对原始数据集进行筛选
Background
作者将VLM从模型和数据的角度进行了分类
- model perspective:Encoder based(投影到同一表示空间进行对齐)很难完成图片文本标注任务,Encoder-Decoder based
- Data perspective:借助充斥着高度噪声的Web数据集进行训练
Method
Overview

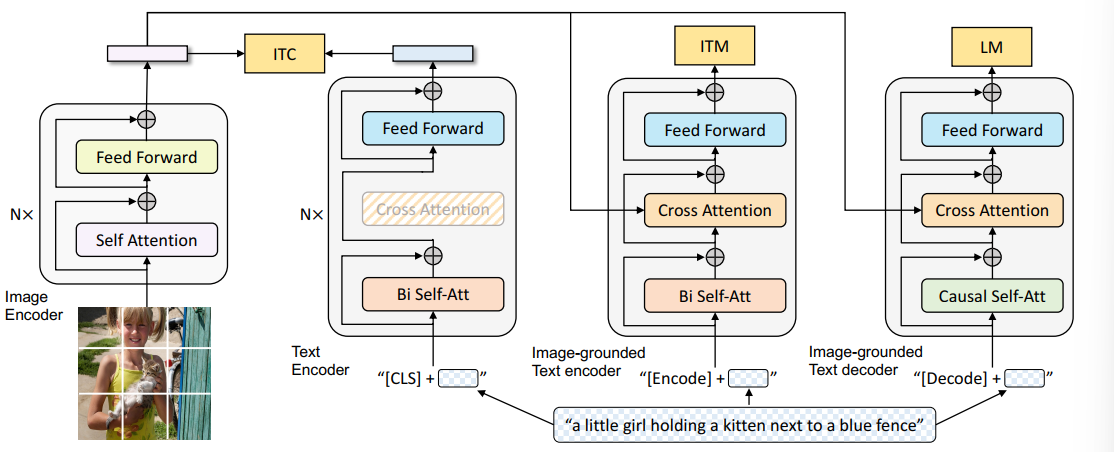
三个子任务
- ITC:视觉-语言表征对齐
- ITM:构建Image-grounded text encoder,将visual编码的sequence和language编码出的sequence计算cross attention,输出的latent representation用于判别image-text pair属于positive/negative pair(二分类任务),选择相似度高的负样本作为negative pair以提升pair表示中包含的信息量
- LM:基于图片的文本生成用于生成描述图像的文本,自回归地进行训练
问题:ITC和ITM的区别在哪里
三个模型
- Unimodel Encoder:单模态编码器,例如Bert/Vit
- Image-grounded text encoder:接收来自另一模态编码得到的序列计算cross-attention,用于编码整个image-text pair,输入的text加上token Encoder
- image-ground text decoder:结构和Encoder相同,区别在于输入text加上token Decoder,以及输入采用Casual Self-Attention进行编码,目的是用上文预测下文
Capfilter
解决缺乏高质量人工图片文本标注数据集的问题,CapFilt包含
- captioner:是一个Image-ground text decoder,基于图片生成对应的文本描述,根据LM目标进行训练
- filter:是一个Image-ground text decoder,基于生成文本和生成文本判断是否为noisy text(判断生成文本和原始文本谁更匹配)
问题:filter的训练依赖一个ground truth文本caption和图片,但是如果直接采用web数据集训练,是否无法避免数据集噪音
capFilt的训练基于一个较小的包含14M图片的文本-图片数据集(但是这种级别的标注数据貌似也很难获得。。)
实验
CapFilt对实验的影响
- 添加Captioner/Filter将会提升性能
- 基于更大的数据集训练CapFilt能够提升性能
Caption Diversity的影响
Nucleaus sampling相比beam search生成多样性更高的caption,包含更多的信息
参数共享
text encoder/decoder结构基本相同,预训练中它们共享除了self-attention层之外的参数
在多个下游任务的实验
图片-文本 检索
BLIP前序工作——ALBEF,通过多模态Cross Attention实现多模态数据表征
Motivation
- 不同模态的数据使用单独的网络编码,无法体现了两者的连续
- 通过cross-attention融合不同模态信息
- 希望不通过高精度的标注数据,而是通过网络噪声数据集进行学习
Model
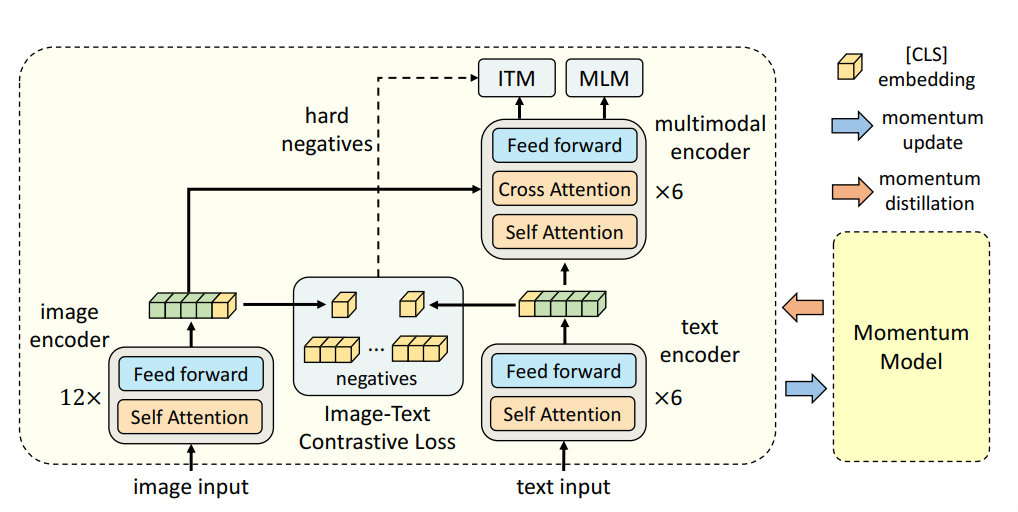
Momentum Model作为一个相较于当前模型较为陈旧的模型用于动量更新,这里使用两个单模态模型提取图片和文本的表征,并使用一个Cross Attention做特征融合
Train
图片和文本被编码为序列
CLS标记一个Sequence的起始Token
单模态图片-文本对比学习
输入一个batch的图片-文本对
采取类似CLIP的方法计算Similarity
Mask Language Model
类似Bert,随机Mask 15%的Token,希望Text Encoder可以预测出Mask的Token是什么
Image-Text Matching
对于图片-文本对的描述设计二分类任务,这里需要给ITM选择负样本,理想的负样本应该满足
- 文本-图片共享类似的语义信息
- 在细节上存在差异
本文利用单模态对比学习的对比相似度从一个batch中选择满足上述两个条件的负样本,即选择一个batch中不匹配但是对比相似度较高的图片-文本对
动量编码器
动量编码器为了解决两个问题:
- 弱匹配弱匹配配**的问题,即文本不太能很好地描述图片语义信息
- 所有负样本被一视同仁地在InfoNCE中被惩罚,换言之负样本描述对应图片的能力不同
动量编码器生成数据的伪标签,包括
- 判断一个batch中文本和图片的匹配程度,对应是一个batch size大小的概率分布,用它代替计算单模态对比损失中ground truth对应的one hot
- 对应MLM任务,生成预测Mask token上的分布
Notes
MLM vs CLM
Reference
两种利用无监督语料训练语言模型的思路
- MLM要求模型根据上下文预测被mask掉的token(理解一段话的含义)
- CLM要求预测下一个token,导致无法感知未来信息(生成模型)
- Seq2Seq是一个Encoder-Decoder架构模型,Encoder编码输入序列,获得中间表示后送给Decoder输出
Nucleus sampling vs beam search
Reference
NLP生成下一个token的采样思路,对于CLM而言选择下一个token对于之后生成的token极为重要,一般token预测会生成和词表大小一样的离散概率分布,从中采样得到下一个token
- Greedy Approach:直接选择概率最高的token
- Beam Search:对于词表长度为10000的长度为10的句子,存在$10000^{10}$种可能性,Beam search每一步选择B个得分最高的token作为候选,选择第二个token是采取同样的策略,即在10000 * B的所有可能性中选择可能性最高的B个next token
- Random Sampling,基于随机概率采样$p_i= \frac{\exp u_i}{\sum_j \exp u_j}$
- Random Sampling With Temperature,引入温度系数t计算带温度系数的概率$p_i = \frac{\exp u_i/t}{\sum_j \exp u_j/t}$
- Top-K sampling 避免选到概率值较低的token,具体做法是仅在概率最高的K个Token中做选择
- Nucleus Sampling:选择下一个token时,希望选择最小的token集合$V(p)$,使得这个集合中token的概率之和大于p $\sum_{x\in V(p)}P(x|x_{1:i-1})\geq p$
- Nucleus Sampling实际上解决了不同概率分布下,K如何进行不同选择的问题
- 这种做法对应真实概率分布,即分布主要集中于少数词汇