StyleTransfer for RL
Gaoustcer
10月 13, 2023
Paper Reading(Style-Agnostic Reinforcement Learning)
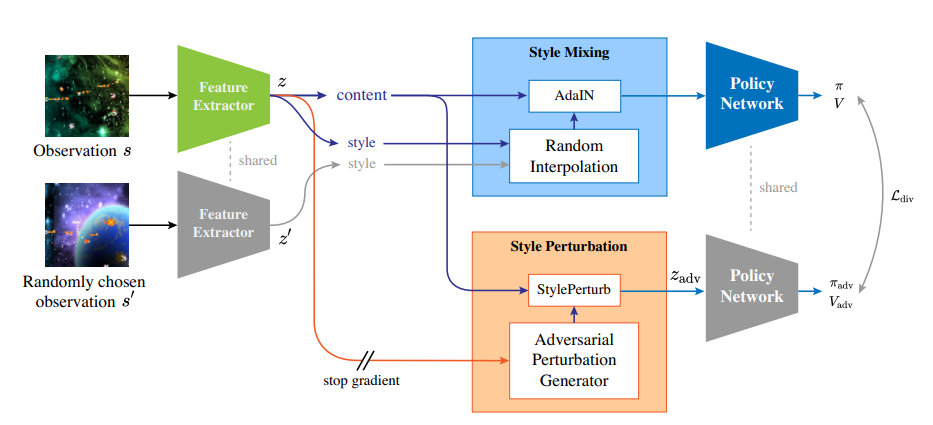
- Style Mixing:根据随机采样得到的Observation进行特征融合作为Policy网络输入
- Style Perturbation:扰动Latent Feature以保证RL模型具有鲁棒性
Style Perturbation Layer
实际上参考StyleNet的基本设计,将Instance Normalization的参数设置为可学习的
SAR Objectives
借助PPO/SAC训练Policy网络,SAC的Actor Loss包括
- 最大化Q值
- 最小化策略熵(倾向于得到确定性策略)
Action Loss写成
next state Value也根据Entropy计算得到,在此基础上定义Divergence Loss,给定的Style Perturb/Style Mixing视觉嵌入$z_{adv}/z_t$,希望policy满足
我们同时希望我们的Adversarial Perturbation Generator能够尽可能在策略上产生较大的扰动,Generator Loss被记作
对于Critic Loss(TD Error)同样构造类似的损失想用于最小化value之间的差异