Gatha
Gaoustcer
10月 03, 2023
Paper Reading: Gatha Relational Loss for enhancing text-based style transfer
Introduction
现有的基于VLM的文本图片生成方法主要基于图片和文本向量方向上的对齐,作者认为这种思路存在两个问题
- 不能解决文本描述和风格出现偏移的情况
- 不能解决风格密爱深度额语义特性
作者提出的方法称为Gatha,具体而言是选择一系列风格模板,目标是
- Source Style Description文本描述和风格化图片应该一致
- 风格化图片和Target Style Description文本描述应该一致
Preliminary of Loss Function
一般的Text-based风格转换目标是
- f style transfer net
- C CLIP Model
dir loss目标是Align图片和文本,content loss目标是保证图像语义在转换前后不变
Method
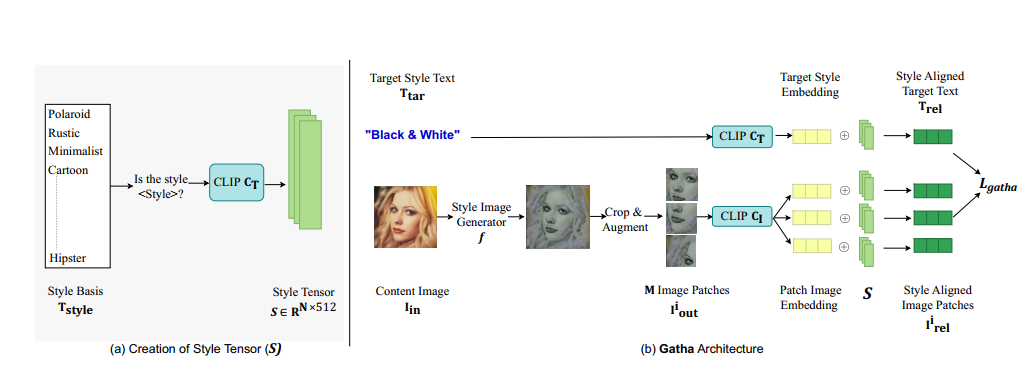
训练Style Senser
收集261个表示Style的转换词(Polaroid,Rustic),将其填入疑问句模板中
1 | Is the Style <STYLE>? |
生成一个Style Tensor S,记作
N是转换词的数量
Relational Loss $L_{gatha}$
给定
- 输入图片
- 目标文本描述
Style Net输出Stylized Image,希望对齐
- 目标文本描述$T_{tar}$和Style Senser的关系 $T_{rel}$
- Stylized Image和Style Senser的关系
Relationship的计算采用向量内积,例如
计算图片-Style Senser关系采用Image Embedding和Style Senser计算内积(采用数据增强+图片分割对输入图进行预处理)
希望两个相关度矩阵差别尽量小
M是划分patch的数量
总结
本文的创新点主要有两个
- 收集了一个以疑问句为模板的prompt全集,之前的prompt主要是陈述句
- 基于1中收集的prompt全集作为中介,对齐图片-style prompt表示