RL4MC
RL4MC:Train An Agent in Minecraft via Vision Language Model and RL Method
MineCLIP
主要贡献
- Minecraft上的开放式任务:此类任务的终止状态不能用程序评估,本文借助基于Mine craft预训练的视觉语言模型评估任务完成的质量,这种评估方式和人类评估结果具有较强的一致性
- 多模态数据集
- 借助多模态数据集训练Video-Text模型
Task Subset
Programmatic Task
给定
- 任务目标的自然语言描述G
- 任务提示(借助GPT3获得)$\mathcal G$
- 初始条件 $\mathcal T$
- 判断任务是否完成 $f_s :s_t\to \{0,1\}$
- 奖励函数(可选) $f_R:s_t\to \R$
Creative Task
只包含任务自然语言描述、任务提示、初始条件,通过人工设计得到了216个Creative Task并将其扩展
- 从Youtube上挖掘任务
- 借助GPT-3生成创新任务
Pretrain Contrast Model in Large-Scale Video
希望文本描述和视频被映射为一个实数,作为当前的reward function
RL with Pretrain Model
给定任务目标的语言描述作为Text Encoder输入,避免多次query VLM导致的开销,作者采取如下策略加速RL训练
- 目标在训练过程中固定,只需要计算一次Text Embedding
- Agent对图像的编码器复用MINECLIP的Video Encoder部分并在训练过程中冻结
- Video Frame Cache:Video Encoder被分成Image Encoder和Aggregator两个部分,对于重叠的Sequence无需重新计算整个Sequence Embedding
- 存储具有高MINECLIP奖励的轨迹并采用类似模仿学习的方式进行学习
Experiment
数据集生成
- 定义实体和关键字集合
- 文本匹配获得对应的text segment,将其扩展为16-77 token
- 在对应的transcript中采样video clip并将其增广到一定时间
集成模仿学习和PPO
维护一个轨迹Buffer $D_{SI}$存储成功/奖励高于某个Threshold的轨迹,在这个数据集上应用模仿学习(PPO Phase and SI Phase)
CLIP4MC
Solved Problem
训练一个Agent,能够完成开放世界中的多种任务。
难点在于无法根据任务不同从环境中提取Task-Relevant Reward
本文希望学习一个VLM,并将其作为Open-Ended Task的奖励函数
Background
视频-文本检索
Fusion Model:融合模型,相当于构建一个神经网络用于计算Text Embedding和Video Embedding之间的相似度
相关工作:CLIP4CLIP
- Video Encoder: 输入多帧图像,输出多帧的图像特征、
- Text Encoder: 直接对文本进行特征提取
- Similarity Calculator(关键)刻画多帧嵌入和文本嵌入之间的相似度模块
给定视频表示$z_i = \{z_i^1,z_i^2,\cdots,z_i^{|v_i|}\}$和问Bern表示$w_j$,计算两者相似度的Similarity Calculator模块如下图所示
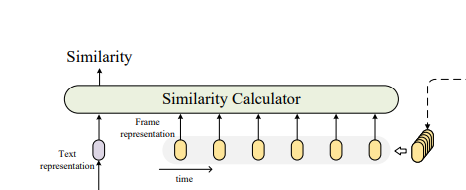
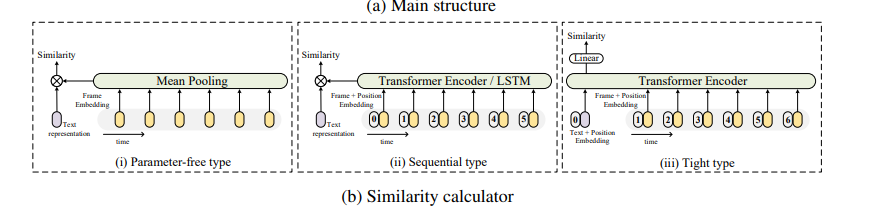
- 取均值
- 采用Text Representation+ Frame Representation + Position Embedding提取特征
- Text Representation也加上Position Embedding
Minecraft dataset
主要难点
- 缺少对数据集的标注
- 对每个frame标注是不可能的
- 很难定义frame完成的具体任务
- action作为Frame的标签,尝试学习一个打标签模型给Internet-scale数据打标签
MineDojo定义了一些Task,将其分为两类
- Programmatic task,存在一些ground truth结果用于判断任务是否被完成
- Creative task,无法定义任务呗很好地完成
本文中更关心前者,MineDojo中直接通过强化学习学习完成某个任务的策略是不可行的(奖励过于稀疏,动作空间很大),因此需要基于Human Demonstration进行学习(Internet Dataset),数据集的格式为

Partial Observable MDP
给定
- 部分可观测状态 $o_t$
- global state $s_t$
- Language Prompt $G$
策略仅仅依赖于部分可观测状态,奖励函数来自过去若干Frame组成的Observation以及Prompt
数据集预处理
Content filtering
- 定义实体名称列表
- 选择长度为L的滑动窗口,作用于Transcript中,希望包含尽可能多的keyword
去除Text描述中的无关特征
Correlation filtering
要求文本描述和视频内容尽可能一致
本文认为避免不一致的策略是选择合适的视频采样方式,解决这个问题的最终方案是借助预训练的MIneCLIP提取视频CLIP特征和文本特征,要求两者尽量一致(top k%)
Motion Encoder
将相隔若干Interval的state作为一个state pair
编码成长度为$T-\delta$的Sequence序列,送入一个fusion model编码为Motion Embedding