Cycle Self-Training
Cycle Self-Training for Domain Adaptation
Background
迁移学习的一个核心问题是学习Domain Invariant Representation,减少了Source/Target Domain之间的分布距离
自训练方法在有监督数据上训练模型,生成无监督数据的伪标签,再用真实标签和伪标签联合训练模型。这种方法的潜在问题是由于Domain Shift的存在导致伪标签存在误差
Mainstream UDA Method
Feature Adapyation
- 基于Source Domain训练有监督模型
- 对齐Target/Source Domain在表示空间上的距离
Self-Training
希望训练的模型在Source Domain和带有Pseudo Label的Unlabelled Target Domain上分类误差尽量小
潜在的问题
- 伪标签存在分布偏移
- 训练过程中伪标签分布发生变化
- 无法判断哪些伪标签是可靠的
Cycle Self-Training
Method Overview
作者分析采用Self-Training失败的主要原因在于伪标签由于分布偏移的存在不够准确
- Inner Loop,基于伪标签训练分类器
- Outer Loop:希望目标分类器在源域中获得更好的表征
和Self-Training的基本架构类似,本文设计的方法包括
- Classifier $\theta$,基于
- Representation $\phi$对原始输入做特征提取
Forward Step
基于标签源域训练分类器$\theta_s$,分类器基于共享表征$\phi$,基于共享表征和费雷其生成目标域上的伪标签
Reverse Step
反向过程用于避免Target Domain上的Pseudo Label出现偏移,基本想法是如果Target Domain上的伪标签和中间表示是正确的,那么可以借助伪标签从Target Domain迁移到Source Domain上,论文中提出基于伪标签$y^\prime$基于共享表征训练目标分类器$\hat \theta_t(\phi)$
Cycle的含义是在Reverse Step优化中间表征,基于Target Domain上训练的Predict head选择合适的特征提取器,使得在源域性能最好
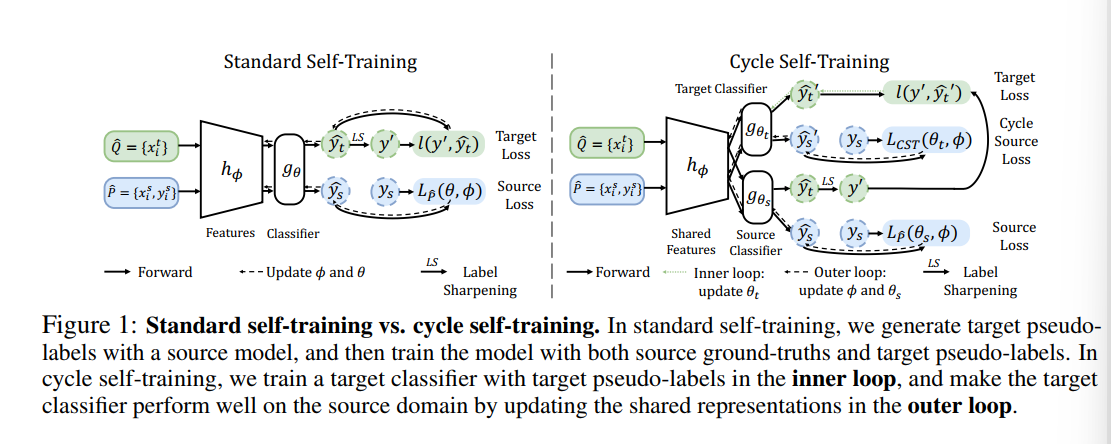
方法示意图,P、Q代表Source Target Domain,两个Domain共享一套特征提取器,基于两个Domain构建两套Classifier Head $g_{\theta_s},g_{\theta_t}$,后者基于Pseudo Label。
损失函数包括两项
- 基于Labeled Source Domain优化Source Domain Predictive Head和Feature Extraction
- 基于第一步训练得到的特征提取器在Target Domain上训练的Target Domain Predictive Head $\theta_t$作用于Source Domain优化特征提取器
由于Target Domain Predictive Head的求解是另一个Minimize优化问题
Two-Loop Optimization
1 | for each outer loop: |
Normalize Model Output in Unlabeled data
定义$\alpha-$Tsallis Entropy
Self-Training的一个重要Trick是在预测Pseudo label时加上Entropy Based Loss以控制Pseudo Lable的置信度,基于Tsallis Entropy在Target Domain上增添Entropy Based Loss