Domain Adaptation via Prompt Learning
Domain Adaptation Via Prompt Learning
Intro && Abstract
Abstract中提出现有解决UDA问题的方法是基于Feature Space采用对抗训练,但是对抗训练容易导致语义信息和标签的丢失(考虑一个极端情况,无论哪个Domain的哪个Image被映射到同一点)
本文的想法是借助Vision Language Model提供的强大泛化能力,将Domain信息嵌入到Prompt中
Method(DAPL)
原本Context Embedding包含$M_1$个Context Embedding
本文借助Domain-Specific Context获取每个Domain上多个Image共享的特征,将Prompt分成DS和DG部分,分别记作
为Domain-Specific token,DS token被一个Domain中的所有Class Prompt共享,不同Domain中Token Embedding不相同
Domain General Token记作
每个Class General Token Embeding不同,这种情况下Domain d中第k个Class的Prompt记作
给定Source Domain的一个Mini-batch
样本$x_i^s$属于第k个Category的概率为
为了泛化到Unseen Target Domain,给定无标签训练数据$x^u$(来自Target Domain),预测其伪标签
我们希望Unseen Target Domain上数据对应伪标签对应的概率尽量大(Target Domain Prompt应该尽量清晰)
损失函数包括两项
- 第一项:借助Supervised Source Domain计算分类损失,记作$\mathcal L_s(\mathcal D^s)$
- 第二项:在Unlabelled Target Domain上计算伪标签,其概率尽量大,记作$\mathcal L_u(D^u) $
和传统表示学习方法不同的是,本文通过两个Prompt$t_k^u,t_k^u$计算标签在原始输入上的条件分布$P(y|x^s),P(y|x^u)$
两个损失函数的本质都是对比学习的Info-nce loss,数据和对应的标签结合实际上构成了一组正样本。Prompt的设计包含Domain General(v)/Specifc(d)部分,同样也可以将Image Encoder分为两个部分,Domain information/DOmain Class Information
论文中给定了一个例子,对于Image $I_1$和两个Prompt $P_1,P_2$,$\lang I_1,P_1\rang$构成正样本而$\lang I_1,P_2\rang$构成负样本,优化对比损失可以让$g(P_1)\approx f(I_1)$,同时扩大$g(P_2),f(I_1)$距离,对于类$(dog,cat)$和domain $(photo,sketch)$,作者生成dog representation和photo/sketch解耦,我认为这是因为作者将其它Domain的相同Class描述prompt也作为负样本
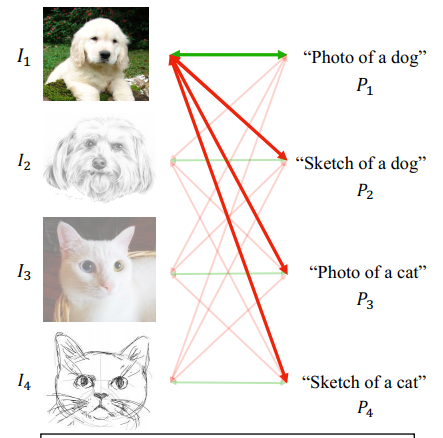
本文给出的例子,因为$P_2,I_1$之间互为负样本,这实际上区分了Sketch和Dog的表征(Disentangle between Domain and Class)