Domain Adaptation and Gradient Reverse Layer
Disentanglement Representation and Gradient Reverse layer
learning Disentangled Semantic Representation for Domain Adaptation
Introduction(False Alignment Problem)
给定两个Domain的数据,一个是真实图片,一个是卡通图片,每个Domain上有两类”pig“和”hair drier”,现在希望学习到的Latent Space的语义是:纵轴代表不同class的分类(Semantic information),纵轴代表图片属于哪个Domain(Domain information),例如

左上角代表真实的pig图片,右下角代表卡通吹风机
实际上模型学到的划分由于样本数据分布的原因并不完全耦合,从分布的角度上看domain latent variable $z_d$和semantic latent variables相互独立,导致产生的分类界如下图所示
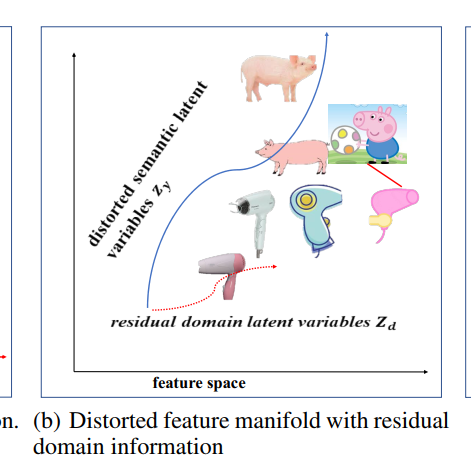
这导致卡通猪被分类到吹风机
Method Disentangled Semantic Representation Model
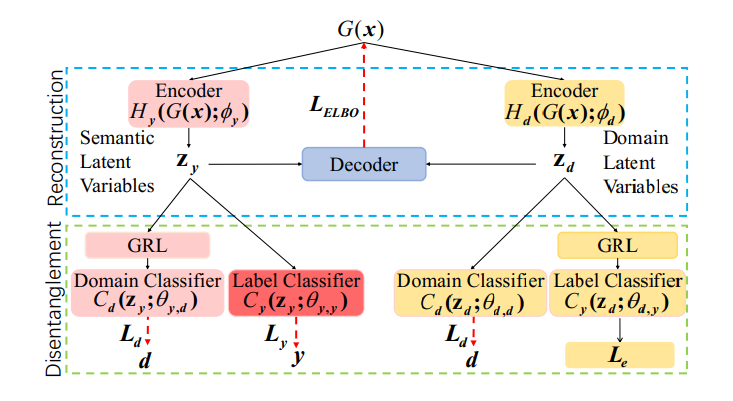
借助classifier实现对抗学习,蓝色部分用于reconstruction,绿色部分用于实现解耦表征
- Encoder网络和参数 $H_y,\phi_y$分别对应编码Semantic latent Variable的网络和参数,$H_d,\phi_d$对应编码Domain latent Variable的网络和参数
- Domain Classifier和Label Classifier,前者$C_d$是一个二分类器,后者$C_y$是一个多分类器,总的想法是Semantic Latent Variable在Label Classifier上尽可能区分(特指在UDA上的数据),Domain latent Variable在Domain Classifier上尽可能区分
通过Reconstruction学习
原始的ELBO中,隐变量z被分解为$z_y,z_d$,通过参数为$\phi_y,\phi_z$的神经网络编码得到,ELBO写成
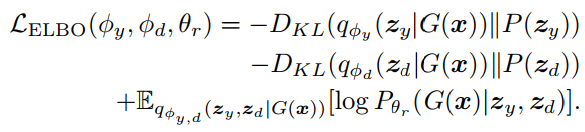
$z_y,z_d$的先验分布都是$\mathcal N(0,1)$
Semantic Latent Variables Disentanglement
设计Domain Classifier($C_d$)和Label Classifier($C_y$)用于从输入中推断Embedding所属的Domain和对应的Label,$L_{sem}$分解为在Source Domain上的分类误差尽量小并且保证Semantic Embedding在不同Domain上不了区分,这个损失函数被设计为
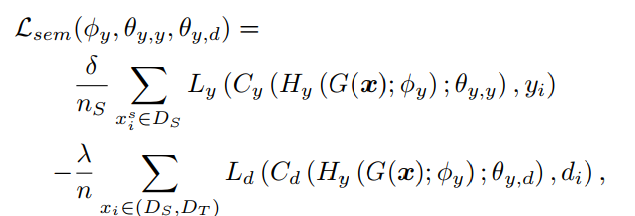
同理针对Domain Embedding优化目标相反,不可通过其推断label,但是可以根据其推断属于哪个Domain,这里不可推断Label是希望推断出的分布熵尽量大(趋近于均匀分布)
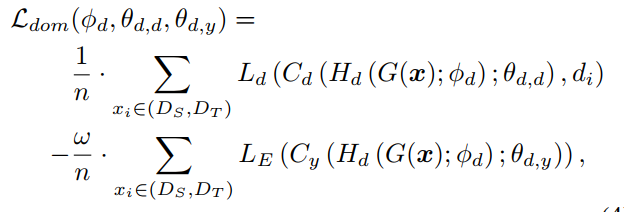
梯度反转和Domain Adaptation
梯度反转最初在DANN中被提出,它的模型架构是
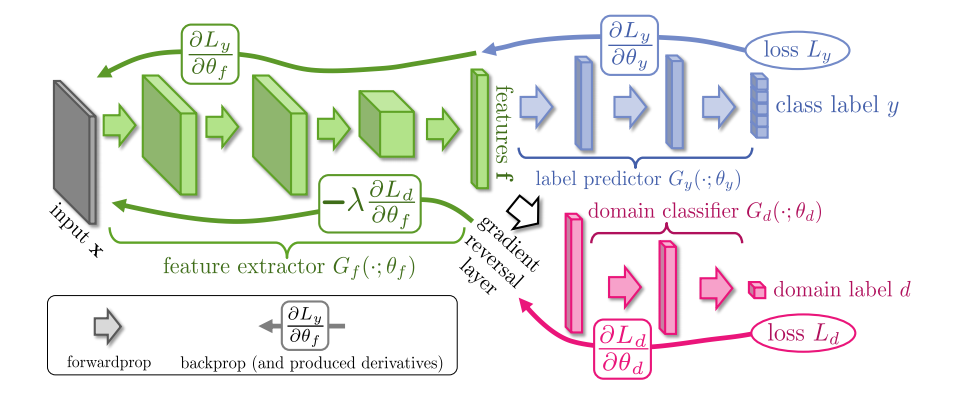
核心思想是:好的特征提取器应该满足
- 不能从输出中推断出输入属于哪个Domain $\max L_y$
- 可以基于输出训练一个Classifier用于推断输入对应的Label $\min L_d$
这两个目标实际上是相反的,目标记作记作
梯度更新满足
避免分阶段训练,DANN中提出梯度反转层
$\lambda$是一个随着训练不是变化的变量,记作
p随着训练的进行从0变化为1,梯度反转主要有两个Motivation
- 避免两阶段训练对抗网络
- 如果采用一般的梯度更新无法在更新backbone参数时根据Domain classifier Loss在计算出的梯度处乘上系数$\lambda$
在backbone和Domain Classifier之间添加一个梯度传播层$R_\lambda$,损失函数记作