TED
Paper Reading(TED,Disentanglement of Representation for Domain Adaptation)
本文提出的基于解耦表示的表示学习可以处理更广泛的state变化,包括
- state变化不影响最优策略(背景颜色)
- state变化会影响最优策略(goal位置)
现有的disentanglement representation需要借助预训练得到好的Encoder,这本身将会降低算法的采样效率。作者分析这些方法需要预训练的一个原因在于在线学习得到的数据并非iid,这将会对模型更新造成困难。TED的贡献在于两点
- 不需要预先收集经验进行预训练,在线学习中借助连续timesteps中的数据学习解耦表征
- 无需Decoder,减少了计算开销
本文借助Disentangle Metric评估表示学习解耦程度的好坏,本文相对于CURL为代表的对比学习的创新之处在于借助state在timestep上的相邻性挖掘了状态转移之间的关系
Relative Work
作者将基于图像的强化学习迁移方法分成以下三类
- 图像增强:作者分析图像增强方法不work的一个原因是训练阶段和迁移阶段的环境变化不一致,即与训练数据和训练环境的相似性高于迁移环境和训练环境之间的相似性
- 学习环境无关表征
- 编码归纳偏置:归纳偏置(inductive bias)指的是在算法训练过程中加入某种先验,必然会让算法更倾向得到满足某些属性的解。我们希望假设的先验和问题本身匹配,否则算法性能将会受到影响。这里的归纳偏置是:算法本身应该对同一个数据的不同augmentation方式给出相似性尽可能大的一组表征
Method
时序上连续的frame作为正样本
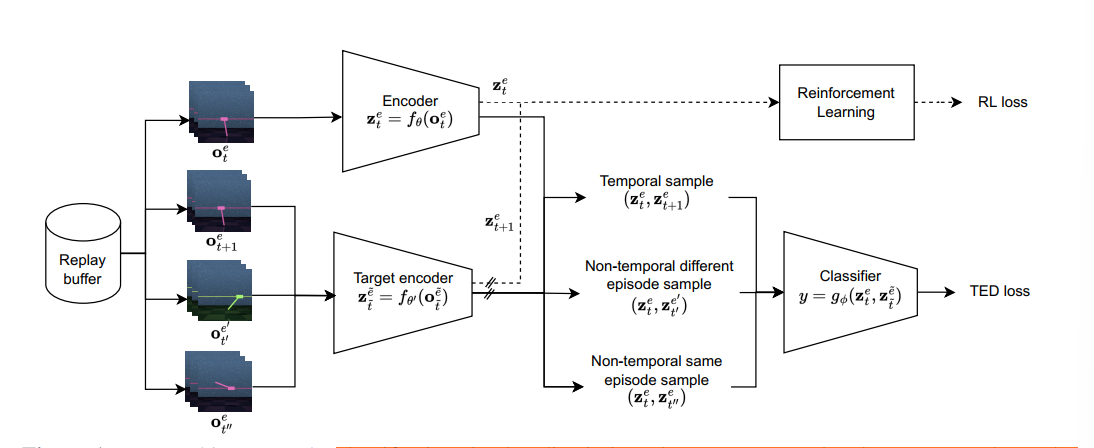
去除Decoder,引入Classifier,输入两个embedding,判断它们是否在时序上连续,输入包含三类
- 时序连续样本$X,x_t=(o_t^e,o_{t+1}^e)$
- 不同episode,时序不连续样本$X^\prime x_t^\prime = (o_t^e,o_{t^\prime}^{e^\prime})$
- 相同episode,时序不连续样本$X^{\prime\prime} x_t^{\prime\prime} = (o_t^e,o_{t^\prime}^e)$
1的伪标签为0,2、3的伪标签为0,基于此训练分类器,计算binary classification loss
强化学习添加辅助损失
基于Replay Buffer采样的一组Transition $B= \{(o_t^e,o_{t+1}^e) \}$,采样得到三组样本,从三组样本中采样observation对
送给分类器输出一个值,作为属于第一类样本的分数,同样$x_t$具有自身的binary标签$l_t$,计算损失函数
classifier应该尽量准地判断输入的state-pair是否在时间上连续
实验
基于Task-Irrelevant observation component的泛化
实验中单个state实际上是多个frame的堆叠,给地一个大小为B的batch中所有observation pair
pair of observations具有的性质是:它们共享一个相似的语义信息(背景颜色),但是在其它语义信息熵有所不同,计算Encode出的张量距离
希望通过$z_{diff} $判断出observation中的哪个语义信息发生了变化
基于Task-Relevant observation的泛化
在100个不同的难度上训练,在另外的100个不同难度上泛化
审稿人的意见
Weaknesses
- TED Loss仅仅用于特征提取,并未和强化学习算法本身结合(完全可以将优化TED loss作为预训练的一部分从而和RL解耦)
- 没有说明视觉环境的不同,审稿人建议作者评估方法在更广泛的视觉差异中的性能(给出的差异化环境例子过少)
- 解耦矩阵如何和performance相结合
- TED损失在实验上的效果并不显著