Domain Adaptation RL(II)
Paper Reading(Domain Adaptation in RL,II)
RL-CycleGAN
本文解决机器人控制中常见的SimtoReal痛点,具体来说在模拟环境中学到的policy并不能在真实环境中很好Work
Idea
借助CycleGAN实现不同Domain上image的映射
构建两个生成器
两个判别器$D_X,D_Y$用于对抗学习Sim2Real
训练Real2Sim类似,这里利用了生成网络的Cycle consistency,即Well Trained生成器应该满足
定义Cycle Loss
基于Cycle-GAN进行Q学习
对于图像任务,s是输入图像,a是采取的动作,目标是最小化TD error
构建两个Q network,$Q_{sim},Q_{real}$分别将仿真输入和真实输入作为state,这样对于6个state
计算6个Q函数
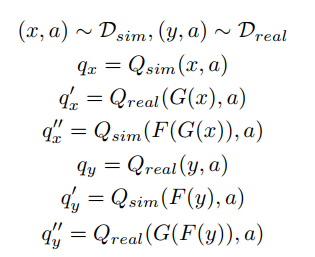
定义RL Scene consistency(state和state变换后的Q值之差尽量小)
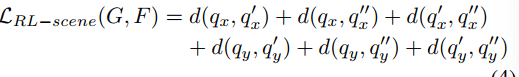
损失函数分成
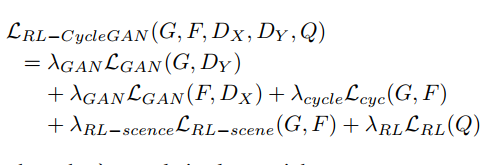
- $L_{GAN}$分类器和生成器对抗生成损失函数
- 恢复输入图片恢复输入图片恢复输入图片*
- $L_{RL-scene}$不同编码器输入sim domain和对应的real domain的结果应该相似
- $L_{RL}$ TD Error
CURL(Contrastive Unsupervised Representations for RL)
本文解决的问题是如何将高维图片输入作为控制信号的同时保证sample-efficiency(一般而言直接用环境的物理参数学习更加高效),这是因为需要额外增加一个net去除pixel中和控制无关的部分
本文解决sample-inefficiency是通过设置合适的代理任务提取state特征,通过在新特征上的强化学习提高sample-efficiency,目前解决这个问题主要有两种思路
- 学习state的好的representation,在新的特征空间上做控制
- 学习好的world-model,在world-model上采样避免直接和环境交互
Background
SAC
sac在获取最大奖励的同时最大化策略熵,训练Q函数loss函数为
Policy Iteration实际上是最大化
Contrastive Learning
给定query q和key的集合
给定K的划分
希望最小化正样本之间的距离同时最大化负样本距离
Method
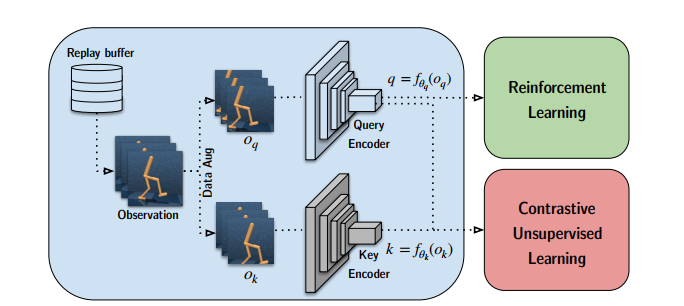
通过data argumentation构建对比学习正负样本(key/query),基于学习到的embedding构建对比损失函数和实现强化学习控制
刻画向量相关性
通过内积运算刻画相似度
W是一个可学习矩阵
算法
给定一个batch的图片x,先通过两种方式进行数据增强
通过两个网络进行特征提取
实际上两个网络结构完全相同,$f_k$依赖于$f_q$进行动量更新,计算$z_q$和$z_k$的相似度
损失函数infoNCE(Cross Entropy Loss)
借助两阶段的训练任务(对比学习预训练+SAC强化学习),可以显著提高基于
DARLA(Imporving Zero-Shot Transfer in Reinforcement Learning)
Solved Problem
对训练阶段没见过的Environment做zero-shot Transfer
是否是新问题
不是,之前的解决方法是通过某种方式学习到不同domain observation的好的表示
之前的解决方案有什么不足
Target Domain上的数据难以获得,如何不通过和Domain Environment做交互实现好的Policy Transfer
本文针对出现的问题提出的解决思路
针对state representation学习任务无关/domain无关的表示,本文将学习分为三个步骤
- learning to see(避免学习到环境的过拟合表示)
- learning to act(利用过拟合表示学习robust策略)
- transfer(基于Target Domain直接做策略迁移)
本文problem setting的基本假设
两个MDP
- $S_S\neq S_T$状态空间相同
- 共享动作空间,状态转移和奖励函数
记号
- source/target domain MDP $D_S,D_T$
- observation space $S^o$,latent observation space $S^z$,前者根据domain的不同记作$S_i^o$
- unsupervised learning mapping function $\mathcal F_U$
Learning Transfer(Disentangled) Representation
DARLA使用$\beta-VAE$学习好的环境表征。$\beta-VAE$本质上是在VAE基础上添加了一个系数$\beta$以平衡重建误差和分布误差
优化:Similarity Loss代替Log Likelihood
很难在整个pixel空间计算重构图像的Log Likelihood
背景介绍:降噪自编码器(DAE)
传统的encoder-decoder假定数据是好的,通过这种方式容易导致过拟合。DAE希望从带随机噪声的输入中学习,以期望提升模型的鲁棒性和泛化能力
DAE方法可以概括为在输入数据上加噪声,噪声有两类
- 满足某种随机分布的噪声
- 随机将输入中的部分tensor置为0(dropout)
借助pretrained DAE修改损失函数
作者先pretrain一个DAE,记作
因为DAE的特性,这个pretrain model具有一定的泛化能力,基于这个特点,作者定义重构误差
重构的图片应该和输入具有相似的Embedding(有一些对比学习的味道)