Domain Adaptation RL
Domain Adaptation RL
Reference
Domain shift
- 分布不一致
- 相似数据的标签发生变化
target domain上的标注很少,单纯在target domain上训练会导致过拟合
Target Domain上的数据大多是无标注的
Basic Idea
训练Feature Extractor Network提取Source和Target中相似样本的特征,在新feature空间上训练分类器
Feature Extractor+Label Predictor
- Source Domain利用标准分类器训练整个pipeline
- Target Domain上的样本和Source Domain映射到Feature Space上具有相似的分布(Domain Classifier)
Domain Classifier以Feature Space上的样本作为输入,判断样本来自Source Domain还是Target Domain(类似GAN)
Label Predictor需要根据Feature预测出Label,因此需要保证Feature Extractor将不同label的图片投影到不同feature(希望Domain Classifier对样本的分类尽量错误,但是个人认为应该用无法分辨更加合适)
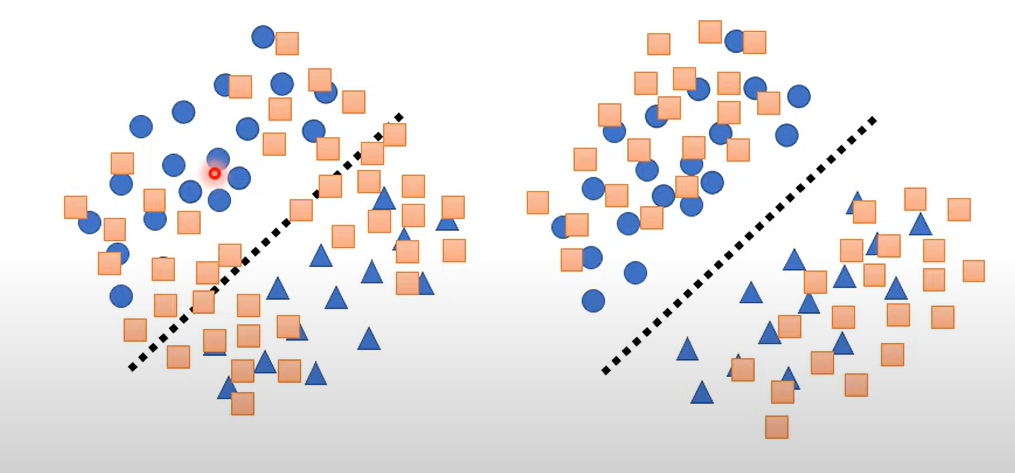
分布相似
最初的损失函数不能约束分布类似左图还是右图
Online Prototype Alignment for Few-shot Policy Transfer
Motivation
RL在进行Domain Adaptation时往往需要学习一个状态的映射函数,本文通过构造状态间的相似度函数计算状态的相似程度,以此为依据对Target Domain中未知状态进行探索。这种方法在target domain和source domain差别很大的情况下效果很好,并且需要更少的source domain中的样本
Problem Setting
强化学习的状态空间由多个object的o组成,记作
每个object有一个标签$o^c$,希望学习到object到prototype
功能功能功能功能功能功能功能功能功能*
对于Source Domain中的object,它的prototype就是$o^c$,记作
对于Target Domain中的object,如何预测不在Source Domain中的object对应的prototype标签是解决问题的关键
学习判别函数$\Psi_{IsUnseen}$
该算子用于判断一个object是否在Source Domain中出现,基本思想是构造一个Encoder-Decoder,用Source Domain中的object送入其中利用Reconstruction Loss训练,这样第一种object映射为
为了获取位置物体的功能,函数$\phi$将物体unseen object根据它的类别标签$o^c$映射到一个新的Prototype集合中,这个Prototype集合和Seen物品中的Prototype集合不相交,记作
无需求解真正的映射,只需知道Unseen集合中物体的Prototype需要被探索得到(Few-Shot学习的目标)
Online Prototype Alignment
设计与Target Domain中Unseen Object交互的探索策略$\pi_{exp}$,注意这个策略在train阶段设计,因此无法和Target Domain中物体交互。在每个训练episode开始时人为设计一种映射,首先随机选择seen object中的一个子集$I\subseteq P_{seen}$,规定映射为
$\psi$是一个随机映射,假定将Prototype $o^p$映射为
在Source Domain中的探索策略$\pi_{exp}$由Source Domain上的交互和$f_{I,\psi}$一起训练得到,应该能通过$\pi_{exp}$域环境交互的信息推断出I中object的prototype,推断模型被记作$q_\theta$,训练的目标是最大化互信息
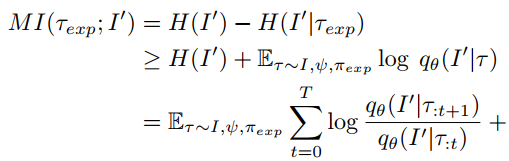
实际上是通过将$\frac{q_\theta(I^\prime|\tau_{:t+1})}{q_\theta(I^\prime|\tau_{:t})}$作为启发式奖励的一部分用于PPO得到的结果,这样在Source Domain上预训练得到的结果将会更好地鼓励policy探索unseen object的功能
为何要选择随机映射?映射的随机性会不会对object prototype判别产生误导?这两个映射的有何区别?
Answer 主要基于鲁棒性考虑
Algorithm

算法总体上分成三步
- 基于Source Domain上的在线策略学习Seen分类器
OFF-DYNAMICS REINFORCEMENT LEARNING: TRAINING FOR TRANSFER WITH DOMAIN CLASSIFIERS(DARC)
本文通过修正奖励函数以弥补Source Domain和Target Domain上的状态迁移的差异弥补dynamic状态迁移的差异
基本假设
只要在Target Domain中存在的状态转换,在Source Domain中必然可能发生
这个假设的意义是什么?如果没有这个假设会出现什么情况?
Method
定义Target Domain上Trajectory的分布
Source Domain上Trajectory分布定义为
核心思想是:我们希望学习到的奖励能够鼓励Source Domain上的探索策略,当产生的轨迹和Target Domain上的轨迹分布相似时给予其高奖励
Design of the reward
通过最小化奖励之间的KL散度学习policy,损失函数定义为
辅助奖励定义为
为了求解Source/Target上的状态转移概率以求出$\Delta r$,设计一个分类器,Transition发生的概率和分类器概率相关
有点类似经典的Domain Classifier思想
分别用两个分类器$\theta_{SAS},\theta_{SA}$预测两个概率,最终策略在Source中探索的Dynamic近似于Target中的Dynamic
Domain Adaptation In Reinforcement Learning Via Latent Unified State Representation(DARLA)
Related Work
- Policy Generalization vs State Representation Generalization
- 前者需要多个不同的source domain
- visual domain adaptation任务本质上的思想是采取类似于image翻译的方法将state逐像素映射到target domain上,建立这种映射的方法可以通过自编码器和对抗生成模型,但是逐个状态翻译不适用于实时任务
- 本文将state space映射到latent space实际上是VAE的中间层embedding
借助Space Embedding实现Domain Adaptation的一些工作
- DARLA 借助$\beta-VAE$将Latent Embedding和Decoder解耦,并基于DAE的重建损失训练
Method:LUSR
状态空间被定义为raw observation space$S^o$和Latent state space $S^z$,后者记作
对于Source/Target Domain,假定
这是一个insight,意味着本文尝试对latent space做一个划分,以得到领域专用和领域通用的状态表征,后者对于泛化具有更强的意义
进一步假设,状态转移和奖励函数只和$\overline {S^z}$相关
学习状态空间的划分(LUSR)
记一个函数$\mathcal{F}$将state space映射到domain general space,先介绍一下cycle consistency
cycle consistency
方向不变性方向不变性方向不变性方向不变性**,一旦训练好,encoder-decoder和decoder-encoder都能恢复编码段输入的数据,假设输入state $s$,中间状态记作$\hat s,\overline s$,则两个过程为
利用cycle consistency学习具有domain general的特征表示
交换两个latent embedding的specific部分交换两个latent embedding的specific部分交换两个latent embedding的specific部分交换两个latent embedding的specific部分交换两个latent embedding的specific部分specific部分**
损失函数分成两个部分
- 随机生成随机生成随机生成成*Domain specific部分所得到的重构损失以及Domain general变量和先验分布之间的KL散度
- reverse:交换Domain specific embedding从Decoder端进行state重构带来的误差
为什么这样就可以保证domain general被学出来(这样有些类似于仅仅采用正样本的对比学习,是否会导致学习domain general的网络坍塌成平凡网络