No negative sample Contrast Learning
Gaoustcer
6月 19, 2023
Contrastive Learning Introduction(III,不用负样本的对比学习)
BYOL(Bootstrap Your Own Latent A New Approach to Self-Supervised Learning)
通过自举(仅仅在正样本之间对比学习)学习好的特征表示,同时避免模型退化
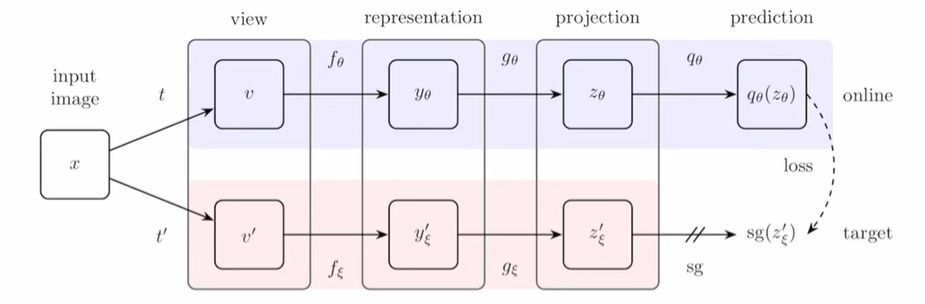
同样的instance通过两个数据增强得到$v$和$v^\prime$,通过两个编码器$f_\theta,f_\xi$和两个projection head $g_\theta,g_\xi$得到representation。使用动量更新$f_\xi,g_\xi$
Predictor
增加一个Prediction Network $q_\theta$(MLP),使得预测结果和$z_\xi^\prime$尽量接近,输出的$y_\theta$用于下游任务
Loss
问什么不会出现模型坍塌
projector/prediction包含两个Batch Normal
Batch Normal会泄露样本中其它数据的特征(和平均数据的差别),本质上是隐式的对比试验
SimSiam(Exploring Simple Siamese Representation Learning)
- 无需正样本
- 无需batch size
- 无需动量编码器
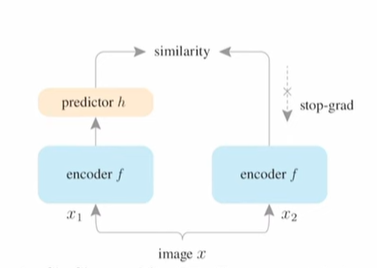
共享参数的两个编码器(没有动量更新,完全copy参数),predictor同时作用于$x_1,x_2$,随后互相预测,计算mse loss
几个工作的对比
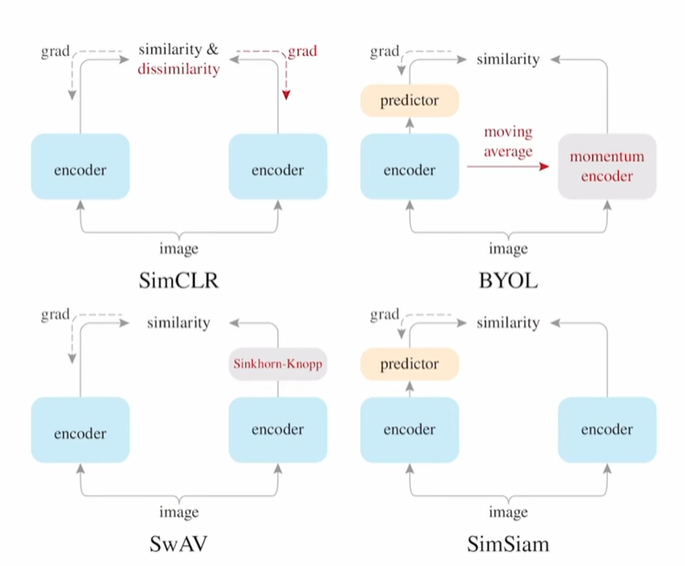
SimCLR和SwAV计算正负样本embedding,优化infonce loss,区别是前者需要迭代两个编码器,后者只需要更新一个BYOL和SimSiam无需计算infonce loss,转化为预测问题,前者采用动量更新保持参数一致性,后者直接采用同一个网络+stop gradient
结合Transformer和对比学习
Moco-v3
解决自监督Transformer训练不稳定的问题,Backbone换成visual transformer,这种情况下大batch_size performance反而不好
随机初始化patch transformer(tokenization,图片序列化)
结合infonce loss和predictive loss
Dino(Self-distillation with no labels)
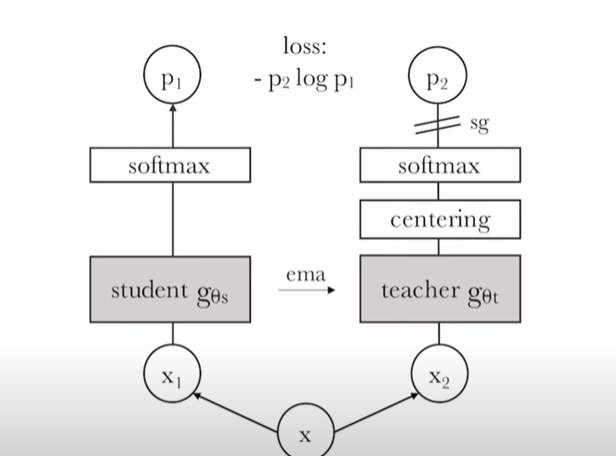
添加centering避免模型坍塌