Moco
Paper Reading(Momentum Contrast for Unsupervised Visual Representation Learning)
无监督学习预训练的结果逼近有监督学习,对比学习用来挖掘instance之间的相似程度
背景
相当于给样本打上伪标签(相似/不相似)
Instance Discrimination
给定一个数据集
对每个instance用k种transformer生成k个增广instance
在$n\times (k+1)$大小的数据集中,instance和它的增广互为正样本(相似),其余样本互为负样本
每张图片自成一类
学习特征,带入NCE loss
动量
加权平均
当前输入依赖于上一时刻状态
Abstract && Introduction
moving average encoder用于提取特征,采用动量更新的方法尽量和上一时刻状态保持一致
Moco学习的特征可以简单地迁移到下游任务
Linear Protocol
测试特征提取网络的好坏,仅仅训练全连接网络作为分类器并在梯度更新时freeze特征提取网络
gap between supervised and unsupervised Learning
对比学习=构建动态字典
对于$x_1$增广得到正样本对$x_1^1,x_1^2$,相对于数据集中其它样本$x_2,x_3,\cdots,x_n$是负样本
两个特征提取器获取特征(也可以借助单一net),字典查询指的是从一些key中找到和query相似的key,这里
- query:$f_1^1$正样本编码出的特征
- keys:$f_1^2,f_2,f_3,\cdots,f_n$,负样本编码出的特征,希望查找到$f_1^2$
重新记作
希望
- 字典尽量大
- 编码器一致性,指的是多个key应该借助相似的编码器生成
为什么用队列代替字典?
队列可以很大,但是每次更新只更新一个mini-batch大小的特征
,尾部特征来自来自**新编码器,尾部特征来自来自**新编码器,尾部特征来自**新编码器码器**
momentum encoder解决不一致问题,它的更新满足
落后于正样本encoder参数
能否将Mask Auto Encoding作为代理任务?
论文精读
- intro部分归纳无监督预训练在CV上表现不佳的原因在于离散/连续信号空间带来的差别,NLP上可以建立关于token的字典
- Dynamic Dictionary: key采样自data,通过encoder编码为embedding,问题转化为字典中query查找的过程
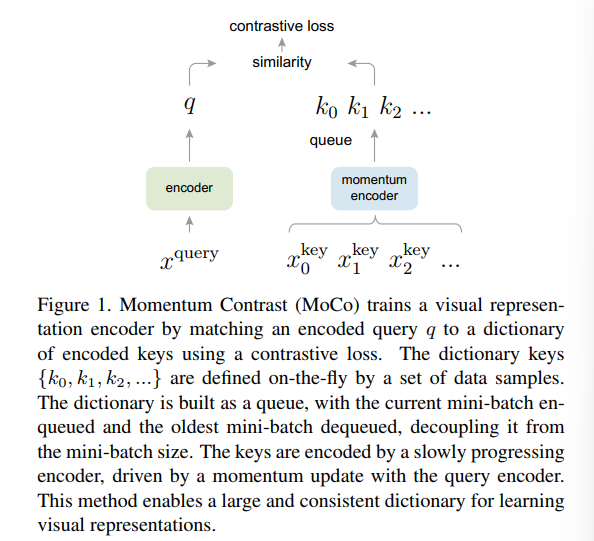
- 字典被视为一个队列,当前mini-batch encode结果入队,旧encoder生成的结果出队。动量更新保证队列中元素的一致性
- can be transferred to downstream tasks by fine-tuning
Method: Contrast Learning as Dictionary Look-up
给定query q和一系列keys $\{ k_0,k_1,\cdots,\}$,其中包含唯一key $k_+$是查询的目标,Contrast Loss用于评估q和$k_+$相对于其它正负样本的相似程度,查询记作
- $f_q$ encoder network
- $x^q$ query sample
Contrast Loss梯度回传的方式 Momentum Contrast
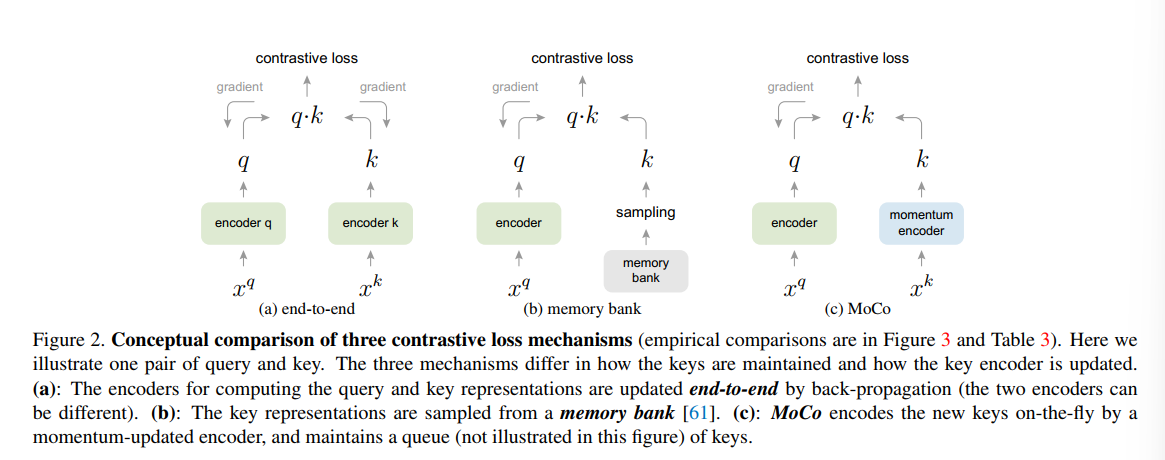
- end-to-end 通过contrastive loss同时更新key encoder和query encoder的参数,两个encoder不共享任何参数
- memory-bank 使用一个encoder,维护memory bank,存储所有正负样本的embedding tensor(从梯度图上detach)。contrastive loss回传每更新一次encoder就重新计算一次memory bank。每次从memory bank中采样若干negative samples
Moco有些类似强化学习中延迟更新的思想,key encoder采用动量更新
Use queue instead of memory bank
队列保证我们可以使用之前encoder的结果,希望key encoder改变不要太大因此使用动量更新的策略
相比memory bank,避免了每次更新encoder都需要重新遍历data sample带来的开销
Pretext Task构建正负样本对
构建正样本对:同一张图片采取两种方式进行数据增强