Contrast and Self-Supervised Learning
Contrast and self-supervised Learning
对比学习希望会减少深度学习任务对数据标签的依赖
Generative && Contrast
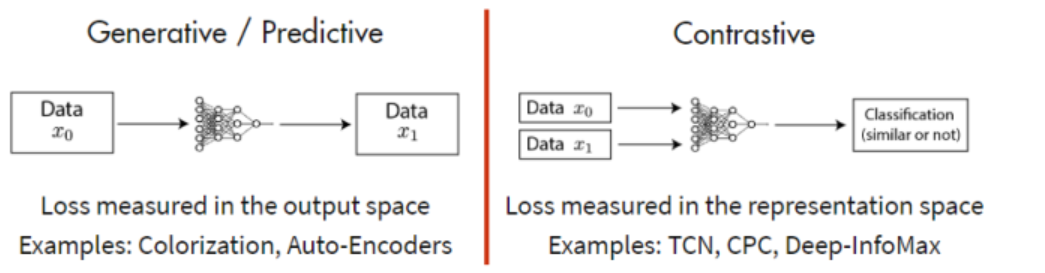
- 生成模型目标是重构输入
- 对比模型目标是获取最优的输入特征
对比学习的目标是
锚定锚定锚定锚定锚定锚定**数据
借助打分函数可以对数据集构建softmax分类器对正负样本进行分类,对比学习往往用于深度学习任务的预训练阶段,随后被用于下游任务(分类,聚类)损失函数设计中
Landscape of Contrast Learning
牢记
- 代理任务定义了对比学习中正负样本,相当于给样本打上label
- 目标函数计算样本之间的距离
算法框架
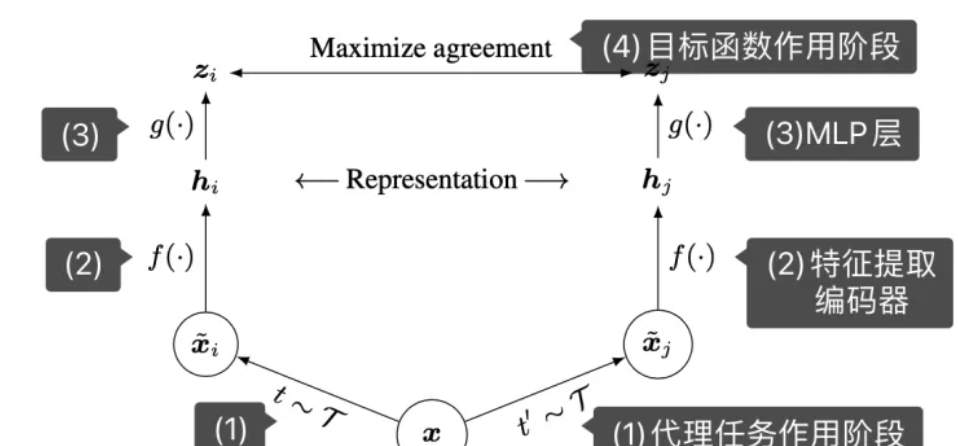
- 对于数据样本x,代理任务生成两个样本$x_i,x_j$(CV中代理任务可以是数据增强,例如给数据加噪声等),$x_i,x_j$称为正样本对
- 特征提取编码,得到representation $h_i,h_j$
- MLP输出representation得到的embedding $z_i,z_j$
- 带入目标函数计算损失
分子是$\exp(sim(z_i,z_j))/\tau$意味着我们希望正样本相似度尽量高,而分母意味着负样本相似度尽量低
$\tau$被称为温度系数,用于控制相似度对损失函数的影响
对齐性和均匀性
- 对齐性:相近样例表示相近
- 均匀性:全体样例均匀分布在高维球面上
正负样例
CV样例正负是从语义角度上考虑的,一个简单的想法是对原始数据进行扰动,同一data point扰动得到的不同数据互为正样例
需要避免扰动改变原本的语义,引入False Positive或者False Negative
对比损失
Triplet loss给定三元组$(x,x^-,x^+)$,刻画正负样本和锚点的相似程度,记作
对比损失没有考虑正负样本数量相差很多的情况,因此引入infoNCE损失
NCE全称是Noise Constrastive Estimation,引入噪声分布,解决多分类问题中softmax分布难以求解的问题。多分类问题转化为二元分类器,判断给定样例来自原始分布还是噪声分布。infoNCE借鉴了这个idea
温度超参的影响:$\tau\to 0$,对负样本区分能力变弱,可能产生False Positive的情况,反之若$\tau\to \infty$,则会导致True Negative
深入理解NCE Loss详情参考
句子模型认为一个word出现的概率可以写成之前word组成的条件概率,比如一个sentence写成
对应的概率是
最大似然写成
Contrast Learning in CV
Instance Discrimination
- 对于已经well training的classifier,输入一张images,输出probability向量中较高的部分暗示不同labels的数据相似
- images clustering的原因可能并非来自语义标签而是pixel层面的高度相似
- 提出了instance Discrimination,目标是将每个instance当成一个class,希望学习图片的内在特征得以区分每一张图片
用CNN将数据映射到低维空间,希望在低维空间上尽量分开,为了训练这个net借助对比学习
- 正负样本:正样本是instance本身,负样本是其它instance
- memory bank,存放所有images representation到一个字典中(128),随机抽取负样本
Invariant and Spreading Instance Feature
- 单一编码器端到端学习
- 正负样本均来自单一batch
,负样本来自负样本来自**instance以外的数据以及经过增强之后的数据e以外的数据以及经过增强之后的数据**
负样本应该尽量多
Contrastive Predictive Coding
针对时序序列
当前时刻t下只能看到
之前的数据,编码得到特征$z_t,z_{t-1},\cdots$,送给Sequential Model获得上下文相关的特征表示
如果$c_t$足够好,应该能用来预测$x_{t+1}$
- 正样本:未来输入
- 负样本:任意给定一个序列不能准确预测
Contrastive Multiview Coding
正样本:views of an object from different perspectives,多个perspective结合才能得到完整的特征
抓住不同视角之间的互信息
选择具有4个视角的数据集,一张图片的多个视角应该互为正样本