Conservative Q Learning
Gaoustcer
5月 12, 2023
Paper Reading(Conservative Q Learning)
学到真实Q值的lower bound,避免因为Bellman iteration带来的误差
Conservative Off-Policy Evaluation
保证Q值的保守估计,目标是
上述两个目标Tradeoff,得到
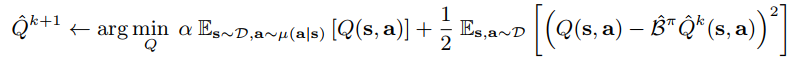
$\mu$是给定的策略,引入行为策略上的价值,得到iteration
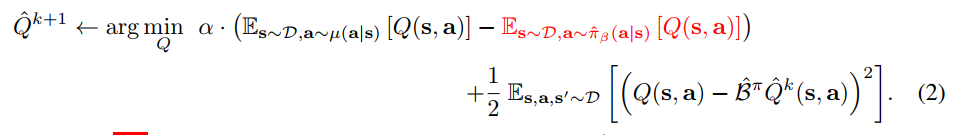
令$\mu=\pi$,得到策略$\pi$下的Q值Conservative Estimationbbb
Conservative Q-Learning for Offline RL
添加关于策略$\mu$的Regulation项,得到
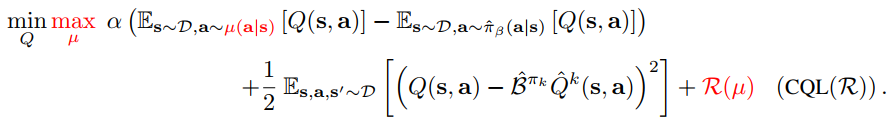
$\mathcal R(\mu)$为给定策略$\mu$和先验策略$\rho$之间的KL散度,先验策略$\rho$是动作空间上的均匀分布
执行$\max_\mu$得到
因此有
策略和Q值迭代写成
- 选择随机策略$\rho$,随机初始化Q函数,得到初始策略$\mu_0$
- 执行$\ref{v}$,得到新的Q函数$Q_1$
- 令$\rho=\mu_k$,按照$\ref{policy}$得到新策略$\pi_{k+1}$
Algorithm

算法中的Equation 4实际上是$\ref{v}$