DALLE
DALLE系列
Zero-Shot Text-to-Image Generalization
TLDR
将图片-文本token拼接起来进行自回归,给定图片$x$,文本标题$y$和token $z$,希望用$p_{\theta,\psi}(x,y,z)$建模三者联合分布,满足
其中
- $\phi$时条件分布$q_\phi(z|x)$的参数,用于从文本中生成(Encoder)
- $\theta$用于从文本描述和token中生成图像(Decoder)
- $\psi$用于刻画图片-token的联合分布
根据ELBO,有
显然目标是从数据集中选择文本-图片对,最大化其下界,第一项对应重构损失
Background:VQ-VAE
解决VAE中间表征用到固定的先验分布,导致模型可控性差,VQ-VAE采用离散中间表征+自回归模型学习中间表征的先验分布,生成过程中在学习的先验分布中进行采样,算法包括
- 图像编码为$z_e$,是$H\times W$个D维向量,在D维向量空间选择K个向量$e_1,e_2,\cdots,e_K$作为codebook
- 对生成的文本token进行聚类(选择最近的codebook代替本身),得到离散的图像编码$z_q$
- 送给decoder
图像生成过程直接采样$H\times W$个连续向量,随后离散化得到$z_q(x)$(在$e_1,e_2,\cdots,e_K$中选择),为了保证局部相关性,需要将不同区域隐变量分布结合起来
Method
训练visual codebook
将输入的$256 \times 256$图像转化为$32\times 32$个tokens,每个token时一个取值范围是8192个离散值,每个token输出在8192个取值上的分布,本质上获取ELBO中的参数$\phi$和$\theta$
对文本进行编码
采用BPE Encoder将文本编码为256个离散token,和文本编码拼接生成一个sequence喂给transformer,transformer输出在$32\times 32 + 256$个token上的概率分布并进行自回归,分别计算在text token和image token上的cross entropy loss并进行加权
推理
生成N张图片,取CLIP score较高的图片作为最终生成结果
训练时基于text和image concat的离散中间特征送给transformer进行自回归预测每个token,生成时mask掉image的特征借助text自回归预测剩余的image tokens,再根据pixelCNN生成图像
DALLE-2
借助CLIP特征实现层级式图像生成(图像分辨率逐渐增加),包含两阶段
- prior 给定文本描述,生成image embedding conditioned on a text caption
- decoder 生成image conditioned on the image embedding(Diffusion)
本文相比传统的基于GAN的图像生成方案提升了生成图像的多样性和真实性,decoder同时保存了风格和语义
overview
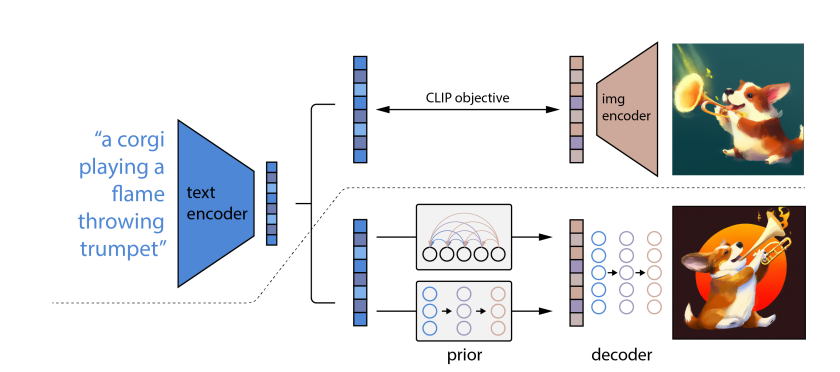
利用CLIP生成的文本特征作为监督信号训练prior,实现文本特征到图像特征的翻译,再翻译为图像(unCLIP)
introduction:图像生成
- GAN Generator-Discriminator对抗学习,输出真实图片,但是缺乏多样性
- 原始图像原始图像原始图像原始图像原始图像原始图像自监督学习)
- VQ-VAE,中间向量做量化,取若干可学习聚类中心(codebook),将中间特征离散化(离散到最近聚类中心)
- Auto-Encoder/VQ-VAE实际上不适合做生成任务,比较适合将中间层特征用于下游任务
- Diffusion:逐步加噪,生成各向同性噪声,再通过reverse diffusion去除噪声
- DDPM:预测生成图$\to$预测噪声,添加time embedding保证共享参数的UNet能够区分去噪的哪一步
- Classifier guided diffusion:在逆向生成的过程中,直接从噪声生成图片不可控,Classifier guided diffusion的提出被用来生成特定类别标签的图片
- 基于带噪声的imagenet训练一个分类器,利用分类器输出的标签梯度辅助学习
- 利用CLIP做文本辅助的图像生成
- Classifier free diffusion:有条件/无条件输出之差,避免训练一个单独的classifier
Method
- encoder视为 text到embedding的映射,decoder视为一种非一对一的embedding到text逆映射
- 翻译翻译翻译译**到image embedding space
给定image-text pair $(x,y)$,定义$z_i,z_t$为其对应的CLIP image/text embedding
- Prior $P(z_i|y)$
- decoder $P(x|z_i,y)$
其实我们想关心的是条件概率$P(x|y)$,可以写成
我们将$x\to z_i$视为某种确定性的映射
Decoder
借助两个Diffusion作为upsampler,将图像从$64\to 256\to 1024$,在每一步的输入中添加噪声提升diffusion的鲁棒性
Prior
基于text预测image embedding
- Auto-regression 离散序列化$z_i$,通过自回归的方式预测caption y
- 借助Diffusion对条件概率建模,记住decoder only transformer监控text sequence到image sequence的映射
实验
根据一张图生成语义相同/风格相异的其它图片

图像风格融合(直接用Decoder,插值两个图像Image Embedding)

图像/文本内插(文本预测出的Image Embedding和图像的从CLIP输出的Image Embedding插值出的结果送给Decoder做预测)

局限性
- CLIP不能理解多个物体的关系(位置,距离),智能理解图片中存在什么物体
- 不能理解词组
- 图像细节缺失
DALLE-3: Improving Image Generation with Better Captions
感觉颇有BLIP的感觉。。
Abstract && Intro
本文提出caption improvement方法训练一个captioner,用于获得更准确的图片-文本标注对,用于解决人工文本标注的数据集不能理解物体关系和忽略背景次要物体的问题,在模型端,被观测为模型不能根据详细的文本描述生成准确的图片
Dataset Recaptioning
给定对大语言模型的描述并将其离散化为n个tokens,记作$t = [t_1,t_2,\cdots,t_n]$,gpt采用自回归范式的文本生成,损失函数写成
为了做Image-conditioned式的文本生成,在序列中引入image embedding $F(i)$(来自预训练CLIP)
Fine-tuning the captioner
- 训练一个小标注器,只能描述图片中的主要物体,文章称这生成short synthetic caption
- 随后再生成较长的标注,包含背景/风格/图片中文本描述
对生成数据集的评估
混合生成和人工标注(ground truth)数据
- 提到了text-to-image生成模型很容易在文本上过拟合,一个例子是如果训练的文本前加上空格,那么在生成时如果文本前没有空格则不能正常生成
- 谈论了text-to-image中的奇特行为,例如对某种单词特别敏感,这种现象被称为bias
- 为了避免这种现象,作者提出regularize文本到人类输入,具体而言混合生成和ground truth文本
评估方法
- CLIP分数
- 使用不同比例的生成文本(short/descriptive)训练生成模型