CLIP4EmbodiedAI
Gaoustcer
1月 10, 2024
CLIP4Embodied AI(Simple but Effective : CLIP Embedding for Embodied AI)
本文研究的问题
本文研究对于输入低维控制指令的Agent(向前移动/转向/向下看/捡起物体),Frozen CLIP Visual Encoder的视觉语义信息理解能力能够对任务完成有多大帮助
本文采取的方法
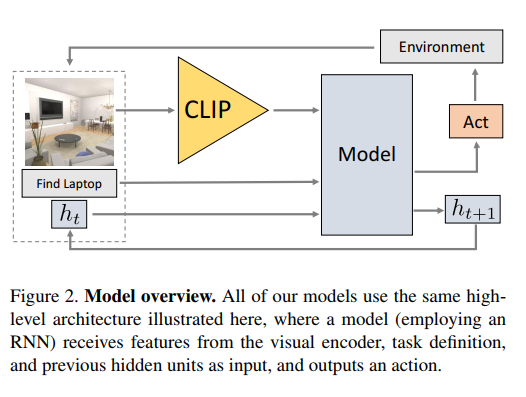
- CLIP输出的视觉语义信息,视觉模型不经过任何微调
- 将第一步输出的语义向量和指令组成的自然语言指令拼接送入RNN,采取自回归的方式预测动作
Visual Encoders in Embodied AI
- 使用大模型可以提升模型在下游任务上的性能
- 参数量增加容易影响Agent在其它任务上的泛化能力
Method
Overview
Experiment
本文讨论四种任务
- 目标导航(两个环境):在环境中探索,希望找到特定类别的物体
- 点导航:导航到特定的坐标,agent具有额外的GPS传感器
- 房间布置 ITHOR:给定整理前后的照片,希望Agent将其复原(不仅是放置在特定的位置,还需要保证物体出于正确的状态,例如笔记本关上)
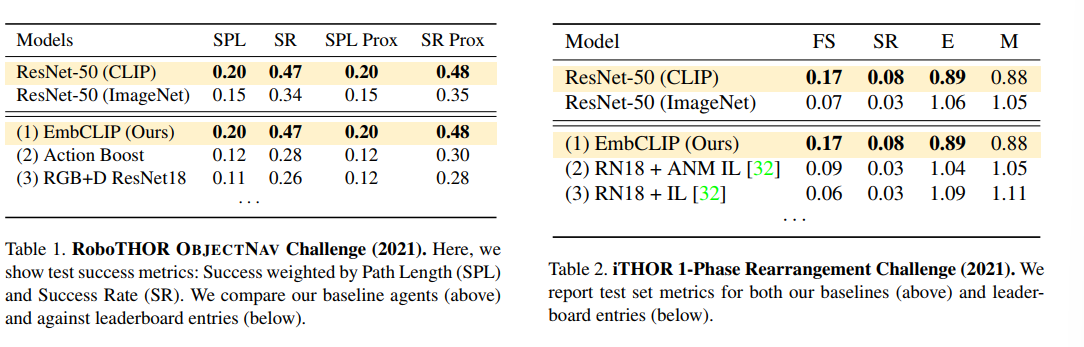
在以导航和物体重排为代表的任务中,CLIP本身对视觉语义的理解帮助很大