paper_share(23-12)
组会论文分享
LLM Implement Policy Iteration
motivation
基于RNN或Transfromer设计RL model可以显著提高模型的性能,作者认为其原因在于这些模型有存储上下文的能力(in-context learning,语言模型中给出一些输入-输出示例,自动迁移到下游任务)
借助语言模型的in-context learning的能力,如何将其应用到RL下游任务中?现在主要基于
- 收集专家数据(human or domain-specific RL agents)
- 借助梯度下降对生成模型进行fine-tune或训练一个Adaptive Layer
Methods
Methods Overview
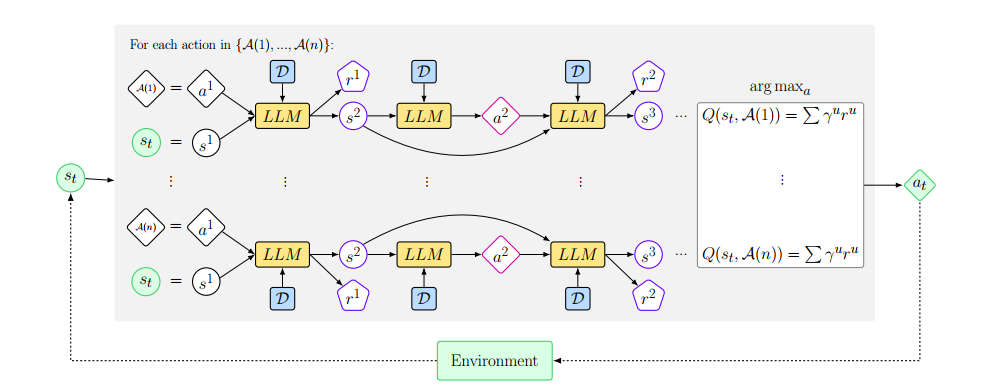
包含两个模块
- Q函数,用于Greedy生成动作
- LLM:根据输入状态和Q函数预测的动作,从预先收集的数据集D中生成下一个状态和奖励的预测
计算奖励估计
将Agent和环境交互的信息存储在D中,从中采样一个状态/动作/奖励对$(o_t,a,r)\in D$,并从LLM采样随后的T组状态-动作对
上述状态/动作/奖励 采样自LLM
直到terminal为True,相当于借助LLM构建了一个World Model,关于用到的四个数据集
- $D_b= (o_k,a_k,b_k)$,其中$a_k = a^u$
- $D_r = (o_k,a_k,r_k),a_k = a^u,b_k = b^k$
- $D_o$仅仅在当前步骤执行$o^u,a^u$预测的terminal不为True的情况下进行(预测终止步无需对下一个状态进行预测)
具体来说如何使用轨迹
- 给出环境的文本描述(状态,动作,终止和奖励),一般是python语句
- 数据集采样最近的c条轨迹
这一部分有关动作价值函数$Q_\pi(s,a)$的估计
Policy Iteration
选择Q值最大的动作
这里的动作选择和LLM的动作选择的区别在于:后者更像是拟合策略函数
实验
Chain
Chain of Thought(Brief Introduction)
利用少量数据提升大模型的推理能力
大模型包含大量的知识,为了将蕴含在大模型中的知识挖掘出来,有三种in-context learning的方式
- few-shot 给定若干上下文(实例输入-输出)
- one-shot 只允许给定一个上下文
- zero-shot 仅仅给出对目标任务的自然语言描述,但是可能存在歧义
few-shot的方法不能解决复杂的推理问题,因此提出Chain of Thought
Chain of Thought
不仅简单描述输入-输出,还需要描述输入-输出之间如何得到的因果关系不仅简单描述输入-输出,还需要描述输入-输出之间如何得到的因果关系得到的因果关系**
Zero-Shot COT
Let’s think step by stepby step**
Motif
Motivation
理解奖励从何而来对智能体的训练,尤其是在离散奖励环境上的训练极其重要。不像人类可以通过尝试判断当前的行为对最终目标的影响,智能体需要对环境进行反复探索以判断动作的好坏。
如何利用high-level knowledge帮助模型决策
Difficulties
- 如何利用非结构化的语言知识(大语言模型)
- 如何弥补语言知识的high-level abstraction和agent所需知识的low-level abstraction之间的gap(intrinsic reward function from LLM,提取两个observation的自然语言描述并根据描述得到奖励)
贡献:
- 描述动作$\to$描述场景
- 利用high-level web knowledge
Method
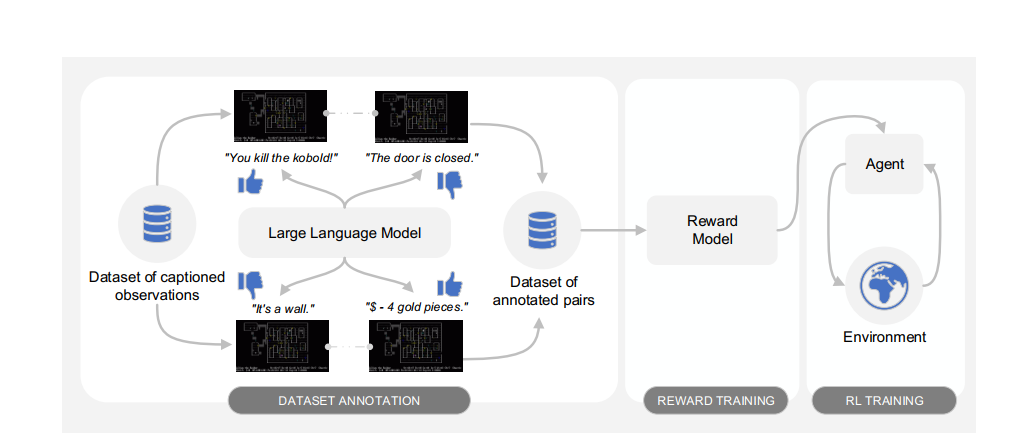
数据集标注
对于Caption文本组成的空间C,定义一个三分类映射
偏好偏好偏好*,偏好实际上代表我们的Agent应该处于哪一个环境
- $Y=1$,代表prefer $o_1$
- $Y=2$,代表prefer $o_2$
- $Y=\phi$,代表两者preference程度差不多
标注通过LLM实现
看出本文的另一个贡献是对Caption之间的偏好代替对observation之间的偏好
训练reward function
训练intrinsic reward model $r_\phi(o)$,采用preference rl
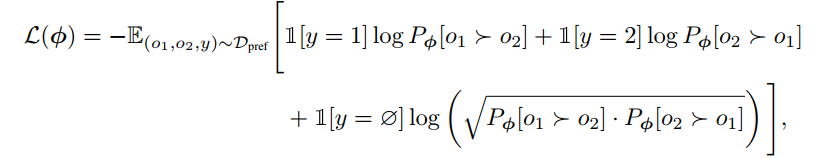
$Pr[o_1>o_2]$记作
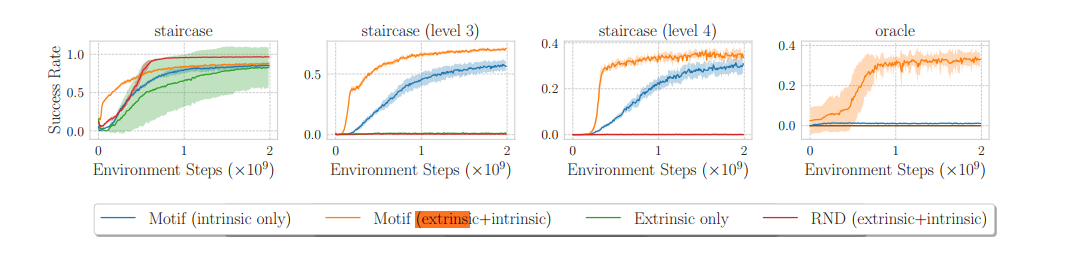
实验
NetHack在屏幕上时不时出现文字提示,表明正在发生的事件(positive/negative),利用这些文字提示作为Caption