Object Detection via Prompt Learning
Design Prompt to Extract Visual Information
RegionCLIP(CLIP for Object Detection)
CLIP学习的是一整张图到文本的映射,没有使用更细粒度的文本描述。本文的主要贡献是基于图片-文本对训练的VLM抽取图片局部语义信息,另外图片的文本描述是不全面的,并不能全面描述图片中所有物体。
Simple Experiment
作者将Clip的Image Encoder作为图片特征backbone,再后面接上目标检测的decision head,输出若干框。对于待检测的目标作者用一系列文本描述,例如
1 | a photo of one cruise |
匹配候选框,发现并不能很好匹配

问题背景:Zero-shot and open-vocabulary object detction
希望基于一些object标注的目标检测器可以泛化到训练集中不存在的物体中
Method
问题分解
作者将目标检测分为两个子任务
- 检测框定位(RPN)
- 检测框内语义信息识别(预训练NLP模型,用于在不同语义概念上扩展)
RPN无需训练,对于一个图片提取出N个候选框
借助视觉编码器抽取出对应的特征图
并池化为同一尺寸,和语言模型编码出的Concept Vector计算匹配分数(余弦相似度)
获取对应区域$r_i$的伪标签$l_j$
How to Pretrain
- 伪标签置信度尽量高,假定区域$v_i$对应的伪标签为$l_m$,优化
借助已有的VLM(CLIP),相当于用CLIP给分割区域打上标签,避免1中伪标签是假的,给定区域$r_i$和M个concept $c_1,c_2,\cdots,c_M$,借助CLIP的Text Encoder和预训练Text Encoder做编码得到嵌入
计算$v_i$在两组Concept Embedding下的分布$q_i^t,q_i^t$,希望两者尽量一致
整张图片计算contrast loss
为什么比单独用RPN+CLIP效果更好?
Can We Improve Segmentation Performance Based on Prompt Design(Learning to Prompt for Open-Vocabulary Object Detection with VLM)
同样采用定位+语义检测分离架构
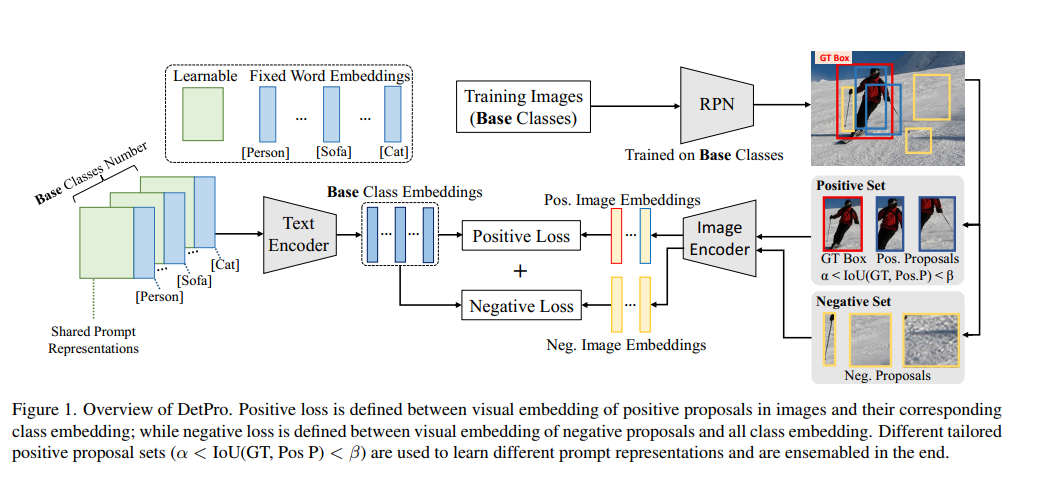
Prompt Design
若干共享表征+固定Class描述
借助CLIP Text Encoder做特征提取
Raw Idea
和RegionCLIP的想法类似将分割后的子图喂给CLIP做分类,本文生成这种在给一个区域打标签的同时直接丢弃了图的其它区域
Context Grading Scheme
IoU在目标中用来评价候选框和真实框的重叠程度,IoU越大目标检测结果越准确,作者提出的基本假设是
不同IoU的候选框应该设计不同的Prompt以进行分类,前景满足
将$[\alpha,\beta]$划分为K份(groups),单独K group
Background Interpretation Scheme
本质上是Context Grading Scheme的延申,IoU较低的区域被认为是背景,Negative Set需要和所有Prompt都不相似
- 预测结果近似于均匀分布
- 创建一个Prompt(背景Prompt)
希望背景框和background prompt对齐
Loss Function
Positive Function计算前景候选框Visual Embedding和对应IoU Conditional Prompt
Negative Function计算背景候选框Visual Embedding相对于Background Prompt的Info NCE Loss
Positive Function需要学习$K\times N$个Prompt,K是IoU划分的数量,N是待分类的物品
Domain-Aware Detection Head with Prompt Tuning
Prompt Design
- Domain Invariant Token $V^c = [v_1^c][v_2^c]\cdots [v_M^c]$,学习M个Token,Domain之间共享,共需要$M\times C$个Token
- Domian Specific Token $V = [v_1^d][v_2^d]\cdots [v_N^d]$,学习N个Token,Domain Specific Prompt,共需要$M\times D \times N$个Token
- class description $[c_i]$
- domain description $[v_i]$,描述Source Domain和Target Domain
- M,N token length
- D Domain Number
- C Class Number
Loss Design
记$t_y^d$为Domain d中标签为y的Prompt,计算InfoNCE Loss domain d中image region $r_i^d$对应prompt为$t_y^d$,正样本为$(r_i^d,t_y^d)$,负样本包括
- 同一个domain $d$中其它Prompt
- 其余domain中所有Prompt
本文定义了Domain d中Image pitch $r_i$相对于Domain集合D的Prompt分类概率
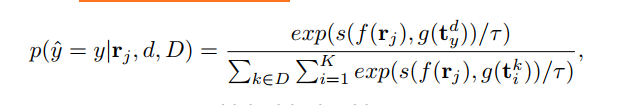
定义Source Domain中Loss
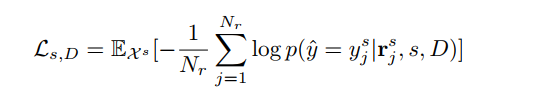
特殊情况
对于Unlabelled Target Domain,由于缺乏标签,作者选择置信度大于某个阈值$\tau$的预测结果作为伪标签以优化Target Domain Prompt
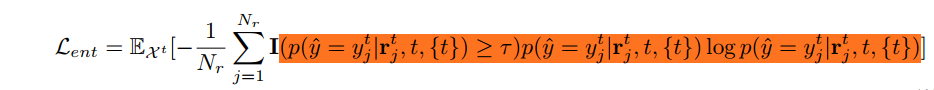
解决优化Prompt早期的Pertubation现象
采用类似动量更新的策略,维护Prompt Buffer
对于Learnable Prompt $T = \{t_i^s,t_i^t \}$,采用滑动平均更新