Diverse Policy in RL
Paper Overview(generate Diversity for a RL Task)
DGPO
提出了一种基于差异的策略优化方法,意在在一个RL Task上获得多种Strategies
在Intro部分,作者提到对话系统意在生成不同风格的回答以提升用户体验,并提出了两种生成diverse rule的方式
- 生成一系列次优策略
- 对于maze环境,存在多个解
生成diverse solutions的方法应该关注四个方面
- 深度学习系统应该获得策略的representation,即一种策略应该可以被一个deep model表示
- 评估策略差异
- 探索探索探索探索*得到Diverse Policies
- Sample Efficiency,同时训练多个策略,通过神经网络共享训练的只是
一些前序工作
- RSPO
- RPG
Related Work
强化学习建模为概率图模型
强化学习一组transition $(s_t,a_t,s_{t+1})$可以建模为概率图
Diversity in RL
训练一个基于latent variable的策略,通过修改条件latent variable可以获得diverse policies
Preliminary
定义Latent Conditional Policy,每个策略$\pi$都condition with latent variable z,定义latent conditional policy/critic
定义disscounted state occupancy
$P^\pi_t(s)$是策略$\pi$在t时刻到达状态s的概率
将RL建模为概率图模型
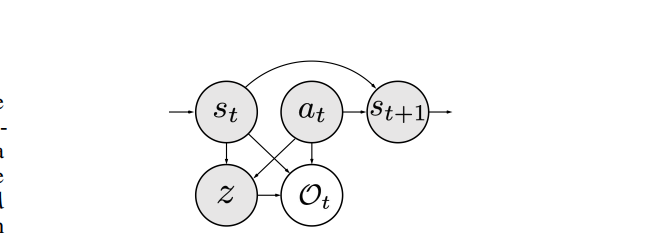
$O_t$表示动作是否是状态$s_t$下的最优动作,应该最大化
根据ELBO,有
基本思想是最大化lower bound实现最大化对数概率
Method
状态s和隐变量z的互信息写成
学习一个神经网络$q_\phi(z|s)\approx p(z|s)$,互信息只能衡量分布在$\rho(z)$上的一组隐变量带来的diversity,在此基础上定义pairwise distance
定义基于discriminator $q_\phi(z|s)$的intrinsic reward
训练一个diversity object
Diversity-Guided Policy Optimization
Critic分成两个部分
同时训练discriminator $q_\phi(z|s_t)$,discriminator通过supervised方法训练,计算$r_t^{total}$
算法
初始化
- discriminator $\phi(z|s):S\to \R^{|Z|}$
- intrinsic critic network $\phi_{\psi_{in}}$
- extrinsic critic network $\phi_{\psi_{ex}}$
数据收集
保存五元组$(s_t,a_t,r_t^{in},r_t^{ex} = r(s_t,a_t),s_{t+1},z)$到replay buffer中
训练
计算$r_t^{total}$
$DIV(\pi_\theta)$是对在latent variable z上分布的一组状态簇的分散程度的刻画
进一步借助intrinstic reward写成
进一步计算$R_{exp}^{total/in /ex}$,基于总的loss训练actor,基于$R_{exp}^{in},R_{exp}^{ex}$更新$\phi_{\psi_{in}},\phi_{\psi_{ex}}$
更新discriminator
Diversity is all you need
去除强化学习过程中的reward,作者提到这样做的好处有
- 稀疏奖励
- reward function很难设计(reward视为一种监督信号,打标签是昂贵的)
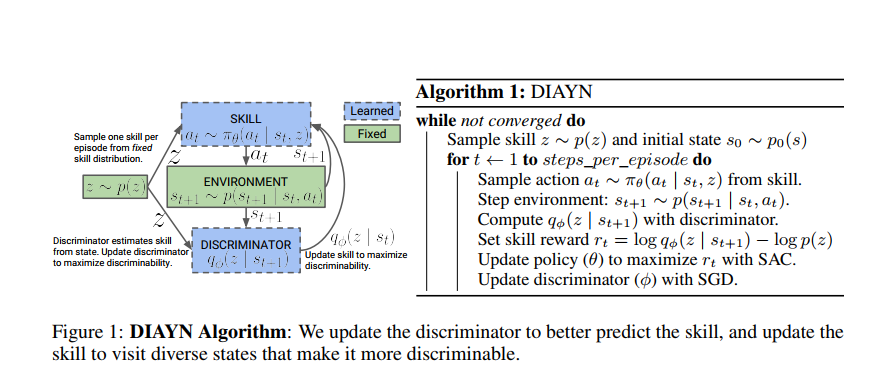
最重要的部分是加入了skill reward作为辅助奖励
论文开头引入skill的概念,记作在latent variable z下的条件策略,基本思想是最大化skill核状态的互信息
实验结果
unsupervised method被用作预训练,预训练的SAC在包含真实reward的环境上performance优于随机初始化
和learn from stretch的区别,实验证明pseudo reward对于best skill接近真实奖励
本文只是一种预训练模式,能否生成multi-policies?感觉很难
Discovering Diverse Solutions in DRL
Latent Policies For Learning Multiple Solutions
Policies conditioned on a latent variable
Trajectory distribution under the latent variable定义为
Q-function conditioned on latent variable定义为
本文希望使用diverse policies提升Agent在few shot泛化上的表现
Latent Representations of Policies
reward包含两项
- environment reward
- mutual information between latent variable and state-action variable
目标写成
互信息定义为
- $H(s,a)$,联合熵
- $H(a|s,z),H(s|z)$,条件熵
本文证明了Mutual information的lower bound
训练一个classifier q,最大化预测精度,最终RL目标写成
Based on importance sampling
本节讨论了如何仅仅通过优化Mutual information return得到diverse并且reward尽量高的轨迹,基本思想是只对reward和最优策略接近的策略做优化
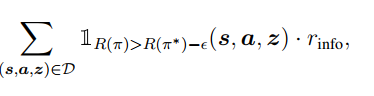
这种方法是sample-inefficient的(因为会丢弃不好轨迹中的所有策略),定义importance weight
目标是不同z采样得到的trajectory reward尽量接近,定义Boltzmann distribution
Z是分布的归一化系数,Boltzmann distribution作为随机均匀采样的修正,解决了采样得到Q值较低Transition产生不好策略的可能性,将其加入Mutual information return,得到
实际的normalize weight是在一个mini-batch上计算得到的,记作
借鉴PPO,本文还对Weight做了clip
Algorithm
实际的

更新Q值估计
y来自conservative estimation of target network
$J_{info}$和discriminator loss有关,基于Q值计算resampling系数,policy被训练为
问题
- max $I(s,z)/I(s,a,z)$